SELinux (Secure Enhanced Linux)
PAM (Pluggable Authentication Modules)
PAM
PAM是一套程序编程接口, 它提供了一连串的验证机制, 只要将需求交给PAM, 然后PAM就会将验证的结果告知客户端. 就像这样:
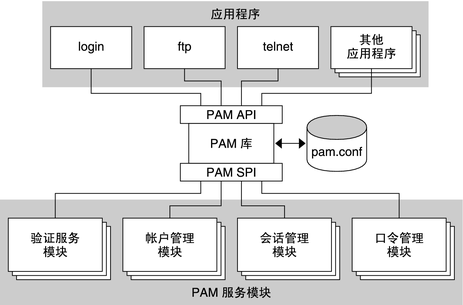
有没有想到什么?对了这个就有一点像OAuth对不, 我们只要发起申请, 接着等到结果就行了, 当然OAuth是多对多, 和这个也是有区别的.但是他们的思想都是一样的, 使得账号密码或者其他的方式验证具有一致的结果, 使得程序员方便处理验证的问题.
如图, PAM作为一个独立的API存在, 用来进行验证的部分叫做模块. 各个模块负责的事情也不一样. 比如在进行密码设置的时候, 会有检测密码强度的提示, 这个就来源于PAM的pam_cracklib.so模块 .
我们就直接以一次密码验证的过程来说说程序调用PAM的工作流程:
- 用户开始执行passwd程序, 输入密码
- PAM到/etc/pam.d/寻找与程序同名的配置文件
- 根据/etc/pam.d/passwd内的设置, 引用相关的PAM模块逐步进行验证分析
- 将验证的结果(成功,失败,其他信息)返回给调用者(passwd)
- passwd根据返回的结果进行下一步的操作.
对于客户端而言, 编码过程和OAuth几乎是一样的.
那么看起来最重要的即使/etc/pam.d/下面的配置文件了, 我们来看一看:
1 | [root@WWW pam.d]# cat passwd |
挨 又是自己的文件结构. 我们来逐行看一下
除了第一行表示PAM的版本以外, 只要后面出现的
#都会被视作注释. 显然易见的PAM将配置分成三个栏目, 分别是:
- 验证类型 ( type )
- 控制标准 ( control )
- PAM的模块和模块参数
下面就结合这三个参数来说一下
第一个字段:: 验证类型
主要分成四种:
auth: 是authentication的缩写, 这种类型主要用来进行用户的身份验证,通常是使用的密码, 所以后面的模块是用来检验用户的身份的
account: 大部分是用来进行授权的, 主要用于进行用户是否具有正确的权限
session: 这个说来应该大家会很熟悉, 只要你经常使用su或者sudo, 当你使用这个进入sudoer的状态, 或者进入其他用户的状态而没有退出的时候, 你就处在一个session里面, 可以去/var/log/secure里面看一下, 会有很多session open, session close的记录(close就说明你logout或者exit了)
password: 就是再说密码, 当进行密码的修改时候就是这个模块发挥威力的时候了
一般情况下, 这些验证到的调用是有顺序的( 因为正常情况下, 你总是要先验证身份, 再进行授权, 接着才有登录, 而在运行时候改变密码 )
第二个字段:: 验证的控制标志
这些标志说白了就是验证的通过标准, 说之前提一下上面例子中的那个include, 这个不是控制标志哦, 只是说这个时候使用后面指定的配置文件的配置. 所以include不是控制标志.
有这些控制标志:
required: 如果验证成功, 就带上一个success的标识, 如果验证失败则带上failure的标识, 但是不论验证结果是成功还是失败都继续验证下去, 这样对数据的日志有利. 所以PAM采用的最多的就是这个标志.
requisite: 如果失败立即返回failure的标志, 直接终止后序的验证流程, 如果成功就继续. 和required唯一的不同就在于处理失败
sufficient: 只要成功就立即回传success的标识, 同时结束验证过程. 但是验证失败的话,会继续过程. 和requisite正好相反.
optional: 不作具体的验证, 而是用来显示信息.
用一张图来表示的话就是这样:

在新版的CentOS7上, 预装的PAM进行了更新, 多了这个控制位:
substack :运行其他配置文件中的流程,并将整个运行结果作为该行的结果进行输出.该模式和 include 的不同点在于认证结果的作用域:如果某个流程栈 include 了一个带 requisite 的栈,这个 requisite 失败将直接导致认证失败,同时退出栈;而某个流程栈 substack 了同样的栈时,requisite 的失败只会导致这个子栈返回失败信号,母栈并不会在此退出.
上面的这些叫做简单机制, 而还有一种叫做复杂机制, 也就是使用一个或者多个status=action形式的组合表示.可以根据不同的返回状态来决定不同的action. 不过说实话啊, 这个机制真心..运维不需要手动的写吧. 能看就行了.
行了, 这样我们就可以看懂这些配置文件了. 在系统的启动中我们说过了getmintty这个程序调用login来提供登录, 那么这个login会不会就在我们的配置文件中呢
1 | [root@WWW pam.d]# cat login |
login也调用了多次system-auth. 迫不及待的打开system-auth:
1 | [root@WWW pam.d]# cat system-auth |
这么多库, 他们都放置在/lib64/security/*里面 如果想要具体了解某些库提供的功能是什么, 还是要查看文档啊. 还是就以这个login为一个例子, 说一下相关的库吧.
| 模块名 | 功能和用途 |
|---|---|
| pam_securetty.so | 限制root用户只能从安全的终端登入系统(安全终端就是在/etc/securetty里说明的) |
| pam_nologin.so | 就是那个大名鼎鼎的nologin文件, 只要存在所有的用户(除了root和已经登录的)就不能再登录进系统了. |
| pam_selinux.so | 可以将selinux(后面会说)暂时关闭, 由PAM来进行验证, 通过了之后就会恢复启动 |
| pam_console.log | 可以使用一些特殊的终端接口来登录系统 |
| pam_loginuid.so | 规范登录进系统的用户的UID(区分系统账号和用户账号) |
| pam_env.so | 用来设定环境变量的库 |
| pam_UNIX.so | 这是一个复杂的模块了, 可以用于验证阶段的认证功能, 也可以在授权阶段进行账号的许可证管理, 并且在session阶段也可以进行日志的记录, 甚至可以进行密码的更新 |
| pam_cracklib.so | 之前也说过了, 这个是用来进行密码强度的检验的 |
| pam_limits.so | ulimits的神奇能力都依靠于这个库 |
行了, 那么就可以来把login的过程讲清楚了.
- 验证阶段(auth):首先,(a)会先经过pam_securetty.so 判断,如果使用者是root 时,则会参考/etc/securetty 的设定; 接下来(b)经过pam_env.so 设定额外的环境变数;再(c)透过pam_unix.so 检验密码,若通过则回报login 程式;若不通过则(d)继续往下以pam_succeed_if.so 判断UID 是否大于1000 ,若小于1000则回报失败,否则再往下(e)以pam_deny.so 拒绝连接.
- 授权阶段(account):(a)先以pam_nologin.so 判断/etc/nologin 是否存在,若存在则不许一般使用者登入; (b)接下来以pam_unix.so 及pam_localuser.so 进行帐号管理,再以(c) pam_succeed_if.so 判断UID 是否小于1000 ,若小于1000 则不记录登录资讯.(d)最后以pam_permit.so 允许该帐号登录.
- 密码阶段(password):(a)先以pam_pwquality.so 设定密码仅能尝试错误3 次;(b)接下来以pam_unix.so 透过sha512, shadow 等功能进行密码检验,若通过则回报login 程序,若不通过则(c)以pam_deny.so 拒绝登录.
- 会话阶段(session):(a)先以pam_selinux.so 暂时关闭SELinux;(b)使用pam_limits.so 设定好使用者能够操作的系统资源; (c)登入成功后开始记录相关信息在登录文件中; (d)以pam_loginuid.so 规范不同的UID 权限;(e)开启pam_selinux.so 的功能.
最后再说一句, 如果 关于这个出现了什么难以解决的不明问题, 最好的解决方法个人认为就是去查看日志, 也即是/var/log/messages和/var/log/secure.(不同发行版不同哦,不确定的话查看rsyslog的配置吧)
SELinux
在开头说过了, SELinux是指安全加强的Linux. 他的来头很大,是美国国家安全委员会负责研发的.
然而在实际的生产环境中却没有**1%**的人选择使用.
美国国家安全委员会对操作系统进行了安全评分, 从最安全的A到最次的D. Windows Server的安全评级为C2, 也就是仅次于最差的D, 那么Linux呢? 和WinServer一样, 都是C2. 有些人总说使用Linux是因为安全, 其实这样是不合理的.只是说由于Linux的学习曲线陡峭导致Linux的用户都花了精力研究过的. 而Windows由于用户中多自然针对的攻击脚本也多.
Selinux工作在内核中, 使用了一种强制访问控制(MAC). 原来的Linux使用的是一种自主访问控制.(DAC)自主访问控制就是说当你的文件想要让别人可以进行写操作的时候, 可以进行chmod, 这种操作Linux系统是不加限制的. 在之前说到进程的时候.说到了一个安全执行上下文的东西, 就是说决定进程能访问那些文件的时候. 我们首先看的是进程的属主, 检查文件的属主和进程的属主是否为同一个, 如果是应用属主权限否则就是其他用户权限.简单的说, 只要用户有权限那么进程就可以访问(有权限)
这一点就给我们的系统带来了风险, 这样的设计已经违反了操作系统中安全法则中的最根本的: 最小权限法则 也就是说一个进程在运行的时候, 如果一共仅需要访问10个文件, 那么最多他所获得的权限就是这10个文件的权限. 就好像说现在的沙箱, 即便进程脱离了我们的控制, 他所能够达到的范围就是这个沙箱的范围.这就没问题了, 但是难度就在于, 我们怎么根据不同的进程来创建不同的沙箱呢? 而且有可能由于SUID等原因, 进程也可能会从A沙箱切换到B沙箱, 因此这么一个安全机制是很麻烦复杂的.
但是并不是所有的程序都需要进行这样的监控.一般像ls这样的程序被劫持的可能性几乎没有, 但是如果是 httpd就不一定了, 作为这种的服务进程应该是被重点关注的对象. 对于SELinux有两种种工作级别.
- strict 严格模式, 每一个进程都收到SELinux的监视
- targeted: 仅有限个进程收到SELinux的控制
我们 知道进程也就是进行文件的读写操作, 但是进程是可以操作进程的就像是这样的:
1 | subject operate object |
我们可以考虑给进程加上一个域(domain)的概念; 接着再给object一个类型的概念.
现在找一个非空的目录试一试, 使用ls- Z 会看到一列复杂的字串, 这个就是SELinux给文件分配的安全上下文环境, 也可以直接就说是文件的一个标签.同样使用ps Z也可以看到进程的标签.
被冒号分割实际上一共有5项但只有前三个比较重要, 所以就先忽略最后面的两个吧.
一个安全标签的基本组成是这样的:
1 | user:role:type:...(omitted) |
所以简单的说, SELinux的工作原理就是基于沙箱, 尽管你有权限访问该用户权限下的所有的文件, 但是你们的标签不符, 因此就会直接拒绝访问.对于进程而言, 第三个type就是进程的域.
那么类型和域是怎么进行匹配的呢?那些类型和域又存在兼容呢?
这些都依靠SELinux的规则库, SELinux事先有一些生成的规则, 你也可以进行规则的自定义.再说这个之前, 还是先谈一下SELinux的验证过程:
当一个进程要去访问一个文件的时候会先开始进行属主的检查, 如果属主都没有权限访问就直接拒绝了, 接着开始进行规则集的匹配, 尝试进行类型和域的匹配. 匹配时还是会针对每一个操作进行权限检查(可以类比数据库) 如果该操作有匹配, 则可以进行 否则直接拒绝, 并进行日志记录.
还有一条, 如果没有规则记录, 那么不论什么情况直接拒绝.
那么就直接来看SELinux的配置吧 主要有这些设定: SELinux是否启用 给文件重新就打标签, 设定某些布尔型特性.
SELinux的启用和关闭
这个之前就提到过了, 在/etc/selinux下的config中, 可以配置三种状态:
1 | # SELINUX= can take one of these three values: |
- enforcing; 强制, 每一个受限的进程都必然受限
- permissive: 启用, 每一个受限的进程违规操作都不会被禁, 但会被记录于审计日志
- disabled: 关闭
只要从disabled到其他任意的状态, 都需要进行重新启动系统(因为要进行重新标签)
相关的命令:
1 | [root@WWW ~]$ getenforce # 获取SELinux的状态 |
这样设定的方法只有当时有效, 重启后会重新变成配置文件中的状态. 另外每次进行配置文件的修改都只有重启系统后才会生效.
安全上下文的修改
现在就将注意点聚焦到之前的类型吧. 一般是要到的情况也只是修改这个文件的类型. 相关的命令就是:
1 | [root@WWW ~]$ chcon # 就是change context的意思 |
那么修改这个类型有什么用处呢 ?
我们直接来看一个完整的实例就知道了:
1 | [root@WWW html]# ps auxZ | grep httpd |
现在直接访问的样子是这样的:

好, 一切正常, 那么现在将他改成root家目录下的类型:
1 | [root@WWW html]# chcon -t admin_home_t index.html |
刷新页面!

出现了403! httpd进程没有访问index.html的权限了.
如果你的页面没有发生变化, 就检查一下SELinux的开启状态(getenforce), 并且注意, 你的SELinux的状态必须是1才行.
把他再改回去:
1 | [root@WWW html]# chcon -t httpd_sys_content_t index.html |
就可以访问了.
如果需要递归的进行打标, 就加上-R参数就行了.
如果要还原文件的默认标签就使用: restorecon SELinux为一些文件都存了默认的标签值, 因此可以很快的进行回复. 同样, 递归的回复的话 就使用-R/-r就行了
接着是布尔型规则的设定, 他的设定和获取就是:
1 | [root@WWW ~]$ getsebool [-a] [boolean] |
SELinux的日志文件都在/var/log/audit里面.
由于现在使用SELuinx的场景越来越小了, 所以我也就不在展开了吧, 更多的东西就这里吧:
更新 17.10.05:
nsswitch
除了上面说过的框架级别的认证服务PAM, 现在再介绍一个框架级别的服务, 即nsswitch 即网络服务交换. 这个服务主要负责进行名称解析 ( name:id )
和PAM一样, 或者说和所有框架级别的服务一样, 当我们需要进行解析的时候, 我们知道有很多种介质, 例如文件解析, MySQL数据库解析, LDAP解析, DNS解析等等. 如果想要支持这些解析, 那么就需要程序员在自己的程序中内置这些解析介质的驱动. 这显然并不好, 所以为了提供一个大家都能够进行解析的平台, 就这样出现了这样的一个通用层, 中间层. 也就是这个通用框架 – nsswitch. 但是我不一定会使用到所有的解析介质. 因此, nsswitch提供一个配置文件来指明解析顺序, 方式. 这样就会通用且灵活. 这种概念在整个计算机科学中各个地方都有体现.
关于nsswitch服务的模块在/usr/lib64/下可以找到, 我们来看一眼:
1 | [root@WWW lib64]# ls libnss* |
其中有dns, nis, nisplus, wins, winbind等等等..
直接切进nsswitch的配置文件吧, 一个条目占一行: 意思也很好懂, 就是什么的解析使用什么方式, 按照优先级(从左到右)来尝试.
1 | hosts: files dns myhostname |
这里我们可以把这个和数据库做类比, 把左边的部分当做数据库名字, 右边的当做键. 所以, 尽管键都是files, 但他们对应的文件是不一样的, 因为数据库不同.
其中有个命令可以来获得对应数据库的某个特定键的值, 例如:
1 | [root@WWW ~]# getent passwd root |
如果不加上特定的键, 就会将整个数据库的值输出. getent的意味: get entry
当然, 找不到是有可能的. 那么找不到怎么办呢, 当然是返回了:
1 | 每种存储中查找的几种状态: STATUS => success | notfound | unavail | tryagain |
这样的一种应用是:
1 | hosts file nis [NOTFOUND=return] dns |
意思是说, 只要nis解析服务可用, 如果没有找到就不去找dns服务了, 而nis挂掉了, 那么就直接去找dns(因为此时nis的返回应该是unavail)
关于nsswitch就是这样吧, 其实没什么