Python后端一锅端.
消息队列 – RabbitMQ
![]()
要明确个的一点是, 所有的消息队列都是异步的.
最简单的一种消息队列模型就是P2P的模式, 一个生产者, 一个消费者, 通过一个队列进行通信.

这种模型有这样的特点: 只有一个消费者和一个生产者, 并且消息一旦被消费就不再存在于消息队列中.当然, 它也是异步的, 生产者在发送完消息之后就可以干自己的事情了.
进阶一点的模型是这样的:

这时我们的任务队列就支持多个工作人员进行分担处理. 一旦任务较为复杂(比如是一个调整图像大小, 渲染PDF等等), 单个消费者进行起来也比较耗时, 而且任务发送的比较密集, 这时就需要进行任务的分担. 当第二条任务发送过来, 而第一个任务还没有结束的时候(C1忙碌, 处于阻塞的状态), C2就会来接手这个任务.
此时应该出现了一些问题了. 如果我们的C1和C2忙碌的工作着, 这个时候突然断电了! 我们的仍然滞留在消息队列中的消息怎么办呢? 因此这里我们就引入一种确认机制以及消息的持久化.
确认机制和TCP的ACK确认特别相像, 只要消息队列收到了确认说明就会将该消息从队列中移除 这样我们就可以确保在消费者死亡的情况下, 任务也不会丢失.
另外, 断电的时候我们的消息队列也会停止, 任务依旧会丢失.
这个时候就要将我们的队列中标记成永久的任务进行磁盘写入 ,在下一次加载的时候进行读取载入, 从而恢复队列.
至此, 我们的消息队列仍然不完整. 因为他缺少一个重要的部件: 消息交换机(exchange), 或者叫他控制器, 随你怎么叫, 现在的模型变成了这个样子:

所有的信息都会经过这个x来进行路由: 根据发送过来的消息上带着的路由标识, 来决定该消息发向哪一个队列. 不仅如此, 我们还可以指定不同的交换类型, 来很方便的进行消息的调度. 此时这些队列都是有名字的队列(要不然向发送对象怎么进行路由啊) 所以为了更加简化这个操作,我们采取随机队列名的方式. 但是这样的话, 我们就不知道怎么进行将信息发送到指定的对象了. 所以这里就又多了一个绑定的概念:

这样我就可以很简单的实现广播了. 不仅这样, 我们还实现了消息队列附加到消息交换机上.
现在已经是一个比较标准的消息队列了! 借由routing_key的特性,我们又可以实现很多不同种的路由交换了:
比如:

在上图的实例中, 我们假象出一种日志发送的场景, 我们一个的队列用来发送所有级别的日志, 而单独提供一条队列仅仅的发送错误级别高的(也就是error).
最后, 再看一下更加深入一点的消息过滤广播模式, 这种模式仍然基于我们上面的routing_key, 只不过我们把这个称作topic :

消息队列另一个高级一点的用法就是远程的过程调用(Remote Process Call, RPC) 这个的组成需要一个客户机和一个可以扩展的RPC服务器:

首先说下回调队列是个什么东西. 上图中的随机队列(就是那个返回给客户的)就是回调队列, 这里面还有一个属性值得关注, 就是相关编号. 这是因为为了能够清晰的我知道哪一个回应对应之前的请求, 不仅如此,如果出现不存在的id, 我们可以进行优雅的忽略或者丢弃. 这种情况是怎么会出现的呢? 当服务端发送回来应答但是在收到客户的应答之前却挂了. 在下一次启动时就会进行重复的发送.
我们的RPC将像这样工作:
- 当客户端启动时, 它创建一个匿名独占回调队列
- 对于RPC请求,客户端发送一个具有两个属性的消息: reply_to: 它被设置为回调队列. correlation_id: 它被设置为每个请求的唯一值.
- 请求被发送到rpc_queue队列
- RPC worker(aka:server)正在等待队列上的请求. 当请求出现时, 它将执行该作业, 并使用reply_to字段中的队列将结果发回给客户端
- 客户端等待回调队列中的数据.当信息出现时,它检查correlation_id属性. 如果它与请求中的值相匹配,则返回对应用程序的响应
至此消息队列(RabbitMQ)的基本就是这样了.
接下来来看一下Python是怎么来和Rabbit服务器进行连接和交互的.
pika – RabbitMQ官方推荐的连接器
RabbitMQ的架构大体是这样:
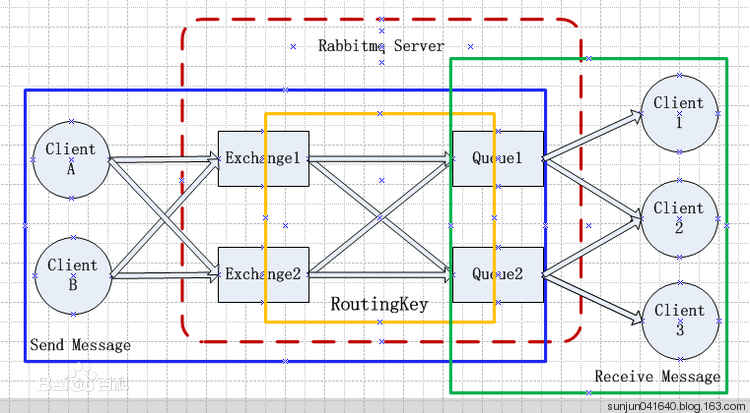
其中几个重要概念: (其中有一些在上面也说过了)
Broker:简单来说就是消息队列服务器实体.
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列.
Queue:消息队列载体,每个消息都会被投入到一个或多个队列.
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来.
Routing Key:路由关键字,exchange根据这个关键字进行消息投递.
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离.
producer:消息生产者,就是投递消息的程序.
consumer:消息消费者,就是接受消息的程序.
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务.
消息队列的使用过程,如下:
- 客户端连接到消息队列服务器,打开一个channel.
- 客户端声明一个exchange,并设置相关属性.
- 客户端声明一个queue,并设置相关属性.
- 客户端使用routing key,在exchange和queue之间建立好绑定关系.
- 客户端投递消息到exchange.
- exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里.
pika是一个第三方的RMQ连接器, 使用起来也很方便. 常规的步骤和上面使用消息队列的方法是一样的.
一个最简单的发布者例子:
1 | import pika |
对应的订阅者例子:
1 | import pika |
这就对应最简单的那一种P2P的模型. 一个订阅者和一个发布者.
那么如何使用pika来进行持久化呢? 很简单, 如果要实现队列的持久化, 只需要在声明的时候声明一下durable属性就可以了:
1 | channel.queue_declare(queue="queueName", durable=True) |
但是, 这只能保住队列的持久化, 却无法使得队列中的消息保持.
如果想要使得消息保持呢? 之前就说了我们只有把想要持久化的消息才保留, 因此我们在发送消息的时候就要明确的说:”这个消息是要持久化的!” 这样的一个功能的实现就是依靠消息的发送类型:
1 | channel.basic_publish(exchange='', |
你注意到了, 在上面的订阅者的那里有一个no_ack的选项设定成了True 这个意思就是说, 不进行收到检查, 也即是说不向服务端发送确认token. 这样所有的消息就会在发送出去之后从队列中消失.
如果将该语句注释掉, 情况就大不一样了, 订阅者必须在每次收到消息之后进行确认回复, 否则. 消息会永久留在队列中, 因为服务端认为该消息没有被客户端收到.
这个时候就要在客户端的回调函数中加上这样一条语句: ( 手动发送一条 )
1 | ch.basic_ack(delivery_tag=method.delivery_tag) |
接着如果我们开了两个消费者和一个生产者的话, RabbitMQ已经默认实现均衡分配任务, 但是假如说我们的任务是偶数耗时长而奇数任务很轻松的话, 就会造成一个消费者疯狂的工作, 另一只就很轻松.
为了解决这个问题也就是每一个消费者都只有一个固定的任务量, 当到达这个限度的时候, 就将后来的任务发送给下一个消费者. 这个任务量我们可以把它叫做服务质量(QoS):
1 | channel.basic_qos(prefetch_count=1) # Let each consumer can only handle one msg per time, 这样每一个worker都只能最大同时执行一个任务了 |
重要提示:如果你使用了no_ack选项, 那么这个功能会失效! 因为这是基于客户应答来判断当前消费者的情况的.
接着我们再来看一下上面的路由交换功能实现. 在上面说消息保持的时候, 代码段中由有一个routing_key这个东西就决定这路由的转发方向, 所以我们可以通过这个实现消息的转发.
来直接看这么一个日志记录的示例:
发送端:
1 | import random |
接收端:
1 | import pika |
这样指明就可以只收到客户想要的类型数据了.
最后一个, 也就是基于topic的消息过滤广播模式, 事实上也就是上面这一种的变体. 所以在代码上也没什么特别的. 唯一的不同就是type改成topic就行.
最后一种应用, 在说具体的实现前, 我们先来把消息的几个常见属性列举一下(属性一共有14个, 但是大部分都很少使用)
delivery_mode: 将消息标记成持久(也就是2)或者transient(任何其他值), 我们在之前说消息持久化的时候提到过这个属性 em?
**content_type: **用于描述MIME的编码, 现在流行常见也就是
application/json**reply_to: **用于命名回调队列. (和 RPC 相关 .这个待会我们会说)
**correlation_id: **( 和RPC相关 ) 用于将RPC响应与请求相关联.
由于我在瞎折腾, 关于RPC的具体实现就省略了吧( 不过基础功能实现了!我只是想再扩展通用化一下(。・`ω´・) ).
Redis
有关Redis的基本使用, 由于以前有过使用并且写了一个简单的上手使用文档.
现在就直接来看实现啦: (这里使用的是**redis-py**库)
连接
连接有两种实现方式.
第一种: – 直接连接
1 | import redis |
但是在使用redis的场景中, 连接是一件很常见事情, 有可能会有大量的连接活动进行.而这样的方式显然是很低效的. 因此一种更常见的连接实现是这样的:
第二种: 使用连接池
1 | import redis |
这样就通过一个一个连接池来进行所有连接的管理, 从而避免每次连接建立, 释放连接的开销 , 并且由于每个Redis实例都会维护自己的连接池, 所以这样也实现 多个Redis实例来共享一个连接池.
操作
String
1 | set(name, value, ex=None, px=None, nx=False, xx=False) |
后面的一些参数也可以有单独的接口来设置:
1 | setnx() # 相当于是nx=True |
多个的设置和获取基本和redis的原生接口是一样的:
1 | mset(*args, **kwargs) |
还有一些多功能的获取和设置:
1 | getset(name, value) |
范围操作: ( 基本和redis的操作是一样的, 略过 )
1 | getrange(key,start,end) |
运算函数:
1 | incr(self, name, amount=1) # 做一个自增操作, 如果name不存在, 那么创建name = amount |
如果对一个不支持运算的字符进行运算会出现: redis.exceptions.ResponseError: value is not an integer or out of range.
如果要在已经存在的值后面进行插入操作, 就是append(key,value) 接口都设置的很好使用
Hash
和redis的哈希操作基本保持一致, 其实大部分的函数执行都是通过Socket远端过程调用( :废话 (`⌒´メ) )
这些最基本的接口签名列举在下:
1 | hset(name,key,value) |
接着就是一些辅助类的接口:
1 | hlen(name) # 获取一个name对应的hash中所有的键值的个数 |
最后再说两个Hash迭代的接口:
1 | hscan(name, cursor=0, match=None, count=None) |
这个是增量式的迭代获取, 对于数据大的数据很有用, 因为这是分片获取的数据, 并非一次性将所有的数据读取完, 他的参数也基本和redis原生的接口保持一致性.
关于这个hscan方法, 在使用的时候你可能会有疑问: 为什么我的cursor始终是0. 关于这个问题.我在使用scan的时候是正常的, 但是一使用hscan的时候就始终都会一次性的把所有的键遍历一遍. 后续解决
封装了一层返回迭代器的方法: hscan_iter 通过封装hscan来创建生成器 由于是二次封装, 因此参数更精简.
1 | hscan_iter(name, match=None, count=None) |
List
基本上都很好记, 过一遍就行了:
基本的操作:
1 | r.lpush(name, *values) # 当然反过来就是 rpush(name, *values) |
辅助方法:
1 | llen(name) # 返回长度 |
堵塞操作:
1 | blpop(keys,timeout=0) # 将多个列表排列,按照从左到右去pop对应列表的元素 |
set
集合的操作:
1 | sadd(name,values) |
sorted list
1 | zadd(name, *args, **kwargs) |
others
1 | delete(*names) |
管道
由于redis-py默认每一次的操作都会创建和断开一次连接( 之前说过优化就是使用连接池 但是这个治标不治本, 因为最后还是要连接池申请和归还释放连接池的 ) 因此 使用管道来在一次请求中指定多个命令, 在默认的情况下pipeline也是原子操作:
e.g:
1 | import redis |
Sqlalchemy
![]()
sqlalchemy是一个超级强大超级复杂的ORM框架, 主要是用来操作MySQL, 也支持sqlite, oracle好像.
这个sqlalchemy说实话, 我感觉在日后的使用中, 我连这个框架的80%都用不到, 认真的. 这个ORM实在是太庞大了. 那么就一些常用功能, 记录用法在下.
我们都知道ORM主要是为了避免直接在代码中插入SQL语句, 另外将数据和对象进行映射, 使得对对象的种种操作可以转换成为对数据的操作, 这个过程由框架完成, 程序员只需要处理熟悉的对象就行了.
现在我们一边复习SQL, 一边将其转换成为Python实现代码.
连接
这个就没有MySQL的代码了, 直接看下sqlalchemy是怎么进行的吧:
1 | from sqlalchemy import create_engine |
很简单吧, 这里使用的连接器是pymysql, 接着写下用户名密码地址数据库名就可以了
后面的参数echo就是说是否进行显示sqlalchemy做了些什么.
创建表
创建表, 就是定义对象的行为, 请看:
1 | from sqlalchemy.ext.declarative import declarative_base |
这样就会将表user创建.
对应的SQL语句是:
1 | CREATE TABLE user ( |
如果想要创建外键约束, 很简单, 这么写:
1 | class Record(Base): |
当然, 这是需要导入的:
1 | from sqlalchemy import ForeignKey |
转换成为SQL语句就是这样子:
1 | CREATE TABLE record ( |
增删改查
首先操作之前, 我们需要拿到一个cursor, 在这里的表现是session:
1 | from sqlalchemy.orm import sessionmaker |
通过这个session, 我们就可以做进一步的操作. 首先来看增加(插入操作). 首先为了插入一条数据, 我们要做的就是创建一个表的实例, 也就是相当于是数据库中的一个条目啦:
1 | user_obj = User(name="Justin", password=password_str) |
此时并没有插入到数据库中.
1 | session.commit() |
现在就可以了.
对应的SQL语句是:
1 | INSERT INTO user (name,password) VALUES("Justin", password_str); |
删除也很简单, 直接把对象实例传过去就行了:
1 | session.delete(user_obj) |
即:
1 | DELETE FROM user WHERE XXXX #(这里就不好表示了...); |
那么更改呢? 得益于数据对象映射, 更改变得再简单不过了:
1 | # user_obj = User(name="Justin", password=password_str) |
对应的SQL语句就是:
1 | UPDATE user SET name = 'Bieber' WHERE name = 'Justin'; |
接下来就说说较为复杂的查吧:
1 | data = session.query(User).all() |
这是最简单的两种了, 其中query方法会返回一个Query对象, 后面的all方法其实就是返回一个list()之后的Query , 而first也就是多了一层判断, 返回list的第一个.
这样查询就和:
1 | SELECT * FROM user; |
一样.
接着看下带有条件的查询:
1 | data = session.query(User).filter(User.id > 1, User.id < 3).all() |
我故意没有写成=号形式, 就是想说明一下这个filter函数的签名:
1 | def filter(self, *criterion): |
这样就可以进行条件查询, 也就相当于是:
1 | SELECT * FROM user WHERE id > 1 AND id < 3; |
还有数目查询:
1 | data = session.query(Admin).count() |
先这样吧. 脖子疼..
来自未来尝试自行实现一个ORM框架的我的补充: 这个地方其实很多细节都没有提到, 例如Python的运算符重载, metaclass等等, 以后有时间可以写点.