Linux的防火墙 – iptables.
防火墙 说道iptables, 自然就会想到这个词 – Firewall . 那么自然就会有一个疑问, 什么是防火墙? 类比我们商场里的防火卷帘门, 防火墙就是起到隔离的作用的.
既然是隔离作用, 那么自然防火墙就会工作在主机或者网络的边缘 这样才可以对进出的网络报文进行检查, 接着而按照使用者指定的规则做响应的决策. 这个防火墙不一定非要是软件, 也有可能是硬件或者两者综合.
在Linux中, 网络功能由内核提供, 所以自然这个防火墙就是工作在内核空间的.
那么, 防火墙是由网卡驱动程序提供的吗? 或者说网卡驱动程序能够提供防火墙的功能吗? 肯定是不能的, 原因很简单, 所谓驱动程序本身是没有理解报文的能力的, 而且作为驱动, 同时提供隔离匹配(这要求理解协议), 这显然是不合设计的. 这样, TCP/IP协议栈十分庞大, 我们到底应该把防火墙的位置放到哪里呢?
我们来顺一遍网络上发向本机的报文是怎么走的: 首先发送到网卡, 接着顺着协议栈经过内核到达注册在某端口上的某应用程序上. 除了这个, 还可能会有目标不是本机, 但是我们负责转发的一种(也就是核心转发). 这也要求经过拆包查看目的地址, 区别在于, 这种情况没有经过用户空间.
反过来, 我们也是可以访问别人的. 这就是发出去的报文, 同样会经过TCP/IP协议栈.
情形很多, 所以我们就不得不在入口, 出口, 转发通道 上都做检查. 这样也就构成了一个防火墙的框架 . 并不是一个单独的软件.
也即是说: 防火墙是设计者在TCP/IP协议栈中精心选择多个地方放置了一些钩子函数 .
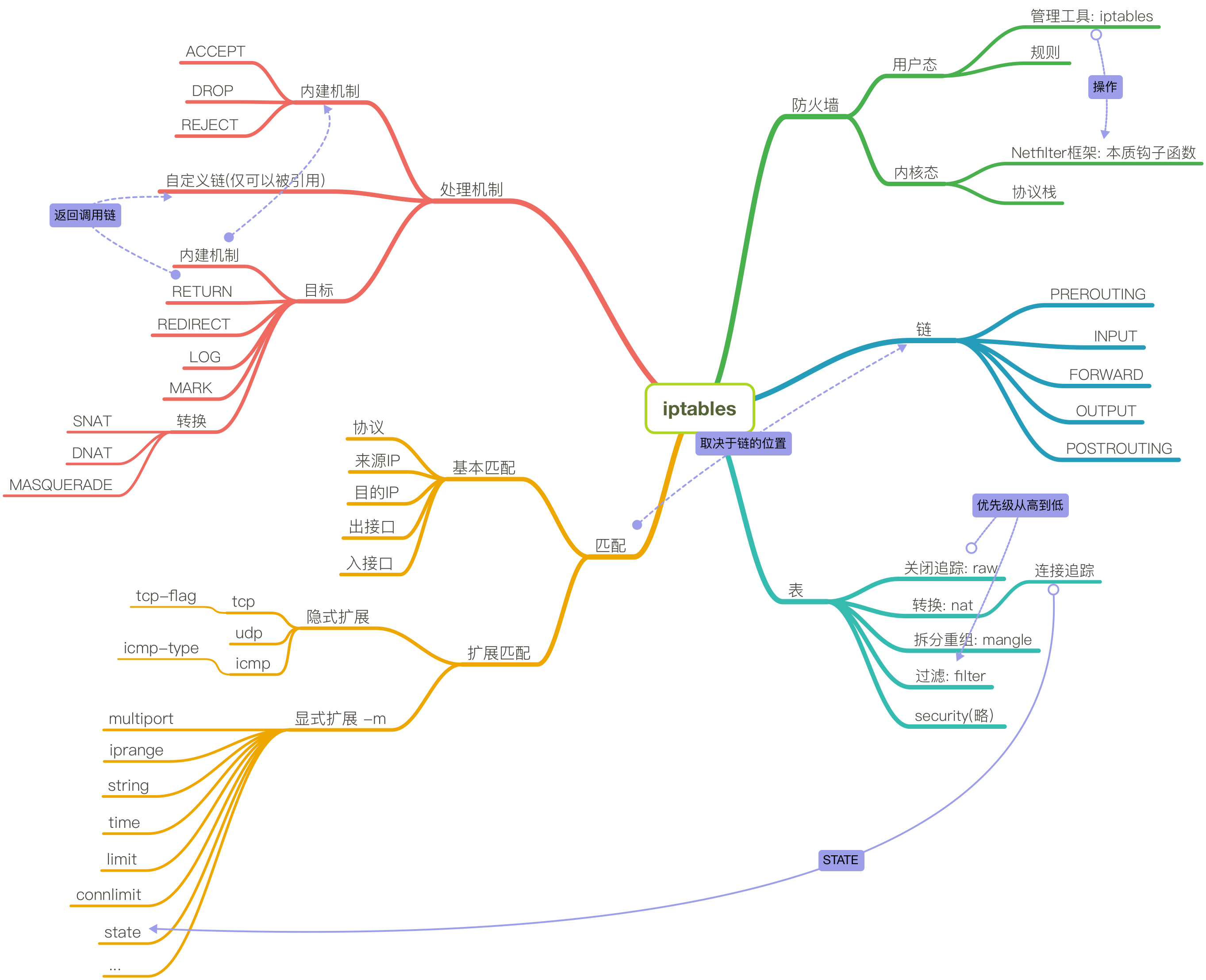
回到正题, iptables是什么? 我们能够使用iptables命令, 这就说明iptables是工作在用户空间的. 我们所说的iptables其实是两个部分构成的:
一个是内核中的钩子, 也就是netfilter
另外一个就是负责管理规则的工具iptables
真正实现拦截检测的框架是netfilter, 但是没有规则, 这些钩子一点用处都没有. 所以他们两个缺谁都不行.
另外, 我们申明一个很重要的点: iptables不是服务, 他没有在你的主机上运行任何进程! 只不过是在开机的时候, 你的配置文件被重新读取了一遍, 规则被重新加载了一遍罢了. 一个在内核中实现的功能, 根本不需要进程和服务!
iptables 现在回到正题, 我们来说说今天的主角. 早期的Linux版本, 内核中是没有这个神奇的小玩意的 而著名的BSD中有一个版本, 号称最安全的BSD发行版中, 存在一个防火墙. 这个时期, Linux刚刚诞生, 所以也模仿着这个做了一个ipfw, 过一段时间之后, 大家发现这个ipfw过于简陋, 也是开始添加一些规则, 规则多了之后就形成了一条条的链子, 因此改名叫做ipchains. 再后来, 为了扩展防火墙的功能, 能使每一个钩子的用法更加多元化.(过滤,转换.) 这样就使得每一个钩子上既有链(行), 又有一条条不同的规则(列). 即形成了一张行列交错的表. 这就是iptables的由来.
之所以叫table, 就是因为他可以过滤(filter), 转换(nat), 拆分重组(mangle), 关闭连接追踪(raw, 不过用的不多,因为连接追踪是防火墙一个很重要的功能, 但是对于前端大并发的负载均衡服务器上,应该关闭此功能), 这些就是我们说的4表.(其实还以一个security功能, 但不常用)
接下来就来说说很多人都听说过的内置的5链:
PREROUTING INPUT FORWARD OUTPUT POSTROUTING
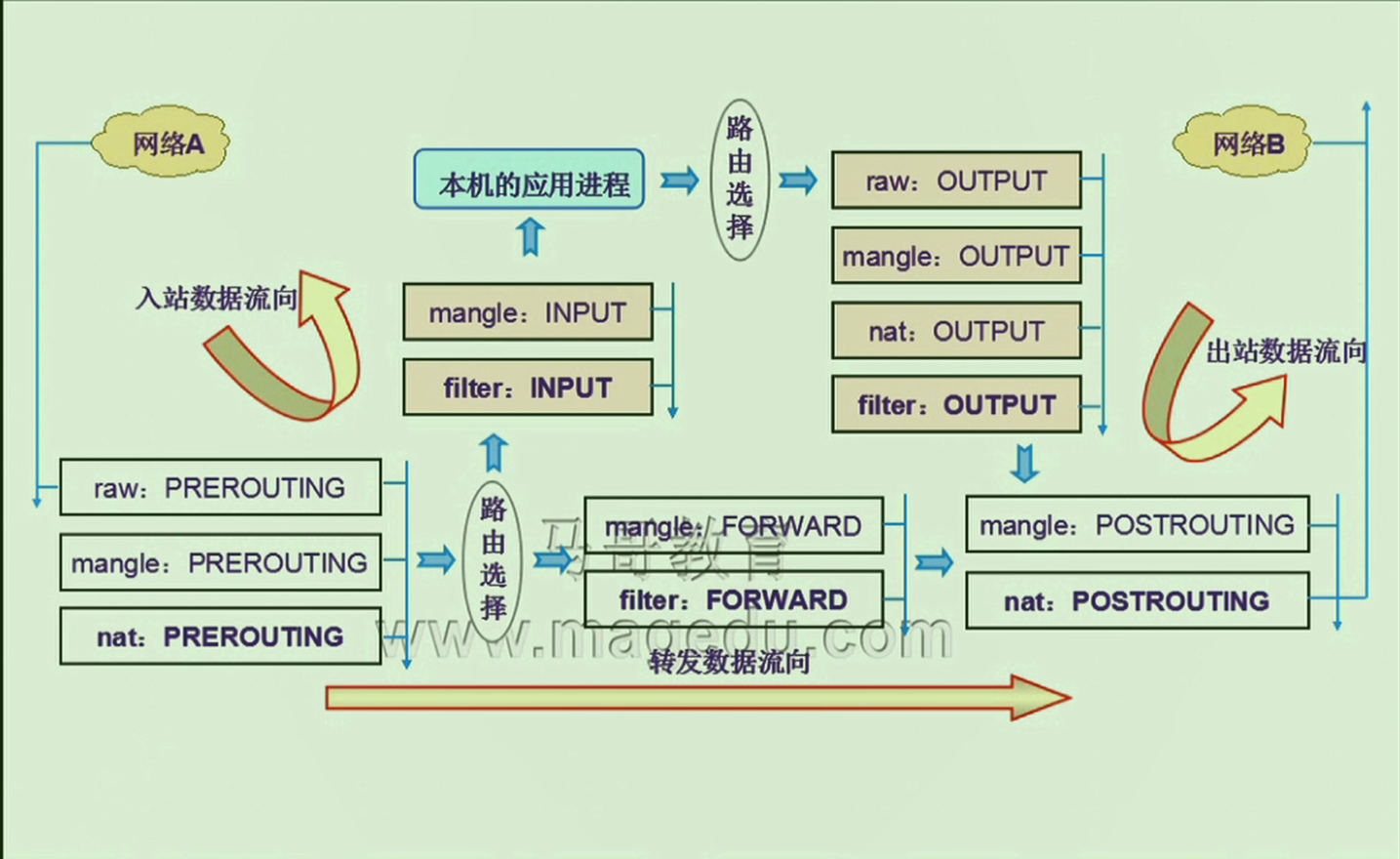
我们报文的状态有以下三种: 流入, 流出, 转发. 其中转发的报文有流出也有流入的. 所有流入的报文都会经过PREROUTING –> INPUT, 而流出的报文会经过OUTPUT –> POSTROUTING, 最后, 转发的报文的状态是PREROUTING –> FORWARD –> POSTROUTING. 这就是对链的说明.
而结合这些链, 对于表的功能, 我们做如下的说明: filter, 过滤的适用范围一般只有INPUT, FORWARD, OUTPUT这些, 对于剩下的两个, 由于有点远, 所以尽量就不做设定. nat仅在PREROUTING, OUTPUT, POSTROUTING这些时刻做设定, raw从功能看, 也仅仅作用在PREROUTING和OUTPUT.
我们用一张图来说明: ( 不知道为什么我在网上找的图都是raw可用于POSTROUTING, 可是实验表明不能, 很疑惑, 可能是版本问题? )
附: 实验结果:
和CentOS7的:
其实在这些过程中, 最令人产生疑惑的地方就是: 路由发生的时刻 就这个问题, 我们来看看:
当报文进入本机的时候, 我们要判断目标主机; 在报文发出之前, 我们要判断经过哪个接口送往下一跳.
这样就对整个报文的流经过程很清晰了, 但是现在遗漏了一个重要的问题: iptables的规则检查机制.
iptables 的法则 链: 链上的规则次序, 即使检查的次序, 因此隐含一定的法则
(1) 同类规则, 匹配范围小的放下面; 比如说: 172.16.0.0/16:ssh ACCEPT 172.16.0.1/16:ssh REJECT. 这个时候就会优先匹配1那一台主机的, 但是如果是172.16.0.2:http ACCEPT就和这些一点关系都没有. 因为不是同类.
(2) 不同类规则, 频率大的报文放上面(优先)
(3) 设置默认策略, 如果没有规则, 则使用默认规则. 有两种: 白名单和黑名单. 白名单也不一定就是放行规则
如同路由聚合一样, 我们也可以将多个规则合并成一个. 这样更快, 更整洁.
还是马哥的图好:
接下来的一个匹配规则就是表级的, 对于一个一个表来说, 有很多链, 这些链的优先级如上图所示, 用文字表示就是:
**raw --> mangle --> nat --> filter **
除了iptables和netfilter, 我们需要手写规则, 这些规则是特定的组成部分的, 首先最必要的就是报文的匹配条件, 说白了就是协议报文的特征指定, 最根本的就是源IP, 源端口,目标IP,目标端口, 这些称作基本匹配. 严格一点的, 我可以进行连接追踪, 状态追踪, MAC探查,甚至硬件特性等, 这些就是扩展匹配.
匹配完毕之后就是处理机制: DROP, REJECT, ACCEPT 这些是内建处理机制, 还有自定义(也就是自定义链)机制. 由于我们的自定义链不能出现在报文流经的地方, 所以仅仅只能通过引用来生效.
iptables能够使我们编辑规则, 接着即时生效, 所以叫做规则管理工具嘛~ 包括添加, 修改, 删除, 显示. 他还可以进行规则编写的语法检查.
有意思的是, 我们的规则和链是有计数器的, 还有两种, 一种就是按照包的个数计数的, 一种就是按照报文大小之和计数的.
OK, 接下来就进入正题.
iptables命令 命令格式很好记:
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@WWW ~] iptables v1.4.21 Usage: iptables -[ACD] chain rule-specification [options] iptables -I chain [rulenum] rule-specification [options] iptables -R chain rulenum rule-specification [options] iptables -D chain rulenum [options] iptables -[LS] [chain [rulenum]] [options] iptables -[FZ] [chain] [options] iptables -[NX] chain iptables -E old-chain-name new-chain-name iptables -P chain target [options] iptables -h (print this help information)
都是一个大写字母跟着一个链名, 把上面的结果抽象一下就是:
iptables SUBCOMMAND CHAIN CRETERIA -j TARGET
现在我们就根据这些主要的子命令来作说明吧 主要分成两类: 链管理和规则管理 (这里先列一下, 后再实验和实例)
链管理 : -F flush 清空规则链, 可以在后面指定哪个链甚至还可以在链后面指定标号, 不指定即清空全表.
-Z zero 置零规则计数器.
-N new 自定义规则链, 创建一条新的规则链.
-X drop 删除用户自定义链, 要求是空链.
-P policy, 为指定的链设定默认策略
-E rename, 重命名自定义链(看参数也能知道是干嘛的hh), 但是计数器不是0的自定义链, 不能改名, 也没法删除.
以上就是链管理 , 接下来就是规则管理 :
-A append 将规则插入到尾部
-I insert 将规则插入到指定位置, 如果不指定位置就是首部
-D delete 删除特定规则, 可以指定匹配条件, 要么通过规则序号, 要么通过指定具体规则.
-R replace 替换指定规则. 通过序号+新规则来实现
除了这些, 还有一些其他的命令:
-L list 列出指定链的所有规则. 其中可以使用-n要求不进行反解, 也支持-v和-vv显示详细信息. 如果不想自己数, 也可以加上–list-numbers来显示规则编号. 还有一个显示计数器计数结果的精确值的选项, 就是-x啦.
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@localhost ~] Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT) target prot opt source destination REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@localhost ~] [root@localhost ~] Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT) target prot opt source destination REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain IN_PUBLIC (0 references) target prot opt source destination
我们在filter表中新建了一个自定义的链 – IN_PUBLIC, 可以很清晰的看到, 只要是自定义的链上面写的都是引用数量, 而凡是内置的几个链上写的都是POLICY. 接下来试试改名和删除:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@localhost ~] [root@localhost ~] Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT) target prot opt source destination REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain OUT_PUBLIC (0 references) target prot opt source destination [root@localhost ~] [root@localhost ~] Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT) target prot opt source destination REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT) target prot opt source destination
如果在-X后面不加参数, 他是会清空所有的自定义链的. 比如我们的CentOS7由一个firewalld服务, 这个会再重启的时候去自动加载一些iptables的规则, 也就是说:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 [root@WWW ~] [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 INPUT_direct all -- 0.0.0.0/0 0.0.0.0/0 INPUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0 INPUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 FORWARD_direct all -- 0.0.0.0/0 0.0.0.0/0 FORWARD_IN_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0 FORWARD_IN_ZONES all -- 0.0.0.0/0 0.0.0.0/0 FORWARD_OUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0 FORWARD_OUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT) target prot opt source destination OUTPUT_direct all -- 0.0.0.0/0 0.0.0.0/0 Chain FORWARD_IN_ZONES (1 references) target prot opt source destination FWDI_public all -- 0.0.0.0/0 0.0.0.0/0 [goto] Chain FORWARD_IN_ZONES_SOURCE (1 references) target prot opt source destination Chain FORWARD_OUT_ZONES (1 references) target prot opt source destination FWDO_public all -- 0.0.0.0/0 0.0.0.0/0 [goto] Chain FORWARD_OUT_ZONES_SOURCE (1 references) target prot opt source destination Chain FORWARD_direct (1 references) target prot opt source destination Chain FWDI_public (1 references) target prot opt source destination FWDI_public_log all -- 0.0.0.0/0 0.0.0.0/0 FWDI_public_deny all -- 0.0.0.0/0 0.0.0.0/0 FWDI_public_allow all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 Chain FWDI_public_allow (1 references) target prot opt source destination Chain FWDI_public_deny (1 references) target prot opt source destination Chain FWDI_public_log (1 references) target prot opt source destination Chain FWDO_public (1 references) target prot opt source destination FWDO_public_log all -- 0.0.0.0/0 0.0.0.0/0 FWDO_public_deny all -- 0.0.0.0/0 0.0.0.0/0 FWDO_public_allow all -- 0.0.0.0/0 0.0.0.0/0 Chain FWDO_public_allow (1 references) target prot opt source destination Chain FWDO_public_deny (1 references) target prot opt source destination Chain FWDO_public_log (1 references) target prot opt source destination Chain INPUT_ZONES (1 references) target prot opt source destination IN_public all -- 0.0.0.0/0 0.0.0.0/0 [goto] Chain INPUT_ZONES_SOURCE (1 references) target prot opt source destination Chain INPUT_direct (1 references) target prot opt source destination Chain IN_public (1 references) target prot opt source destination IN_public_log all -- 0.0.0.0/0 0.0.0.0/0 IN_public_deny all -- 0.0.0.0/0 0.0.0.0/0 IN_public_allow all -- 0.0.0.0/0 0.0.0.0/0 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 Chain IN_public_allow (1 references) target prot opt source destination ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22 ctstate NEW Chain IN_public_deny (1 references) target prot opt source destination Chain IN_public_log (1 references) target prot opt source destination Chain OUTPUT_direct (1 references) target prot opt source destination
说了这么多, 我们还不知道iptables上面的是什么意思:
1 2 3 4 5 6 7 8 9 10 11 [root@WWW ~] Chain INPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 158 12536 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0 3 740 INPUT_direct all -- * * 0.0.0.0/0 0.0.0.0/0 3 740 INPUT_ZONES_SOURCE all -- * * 0.0.0.0/0 0.0.0.0/0 3 740 INPUT_ZONES all -- * * 0.0.0.0/0 0.0.0.0/0 0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate INVALID 2 636 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited ...(omitted)
加了-v参数之后, 我们可以看到计数器了, pkts就是报文数量, bytes就是报文大小, target就是处理方法, 有基本的ACCEPT, DROP, REJECT还有引用特定的自定义链的, 接着prot就是协议, 一般有三种:tcp, udp, icmp. 接着opt就是选项了, 后面两个星其实就是在说接口, 接着就是来源地址和目的地址了, 有的后面还有一段话, 关于这段话的相关 我们在后面再说.
现在发现所有的默认链的默认策略都是ACCEPT, 我们来试着修改一下:
注意: 清空之后 别改INPUT和OUTPUT, 如果你是用SSH在连接的话.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@WWW ~] Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy DROP) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@WWW ~]
接下来就差一个删除操作了, 我们重启firewalld服务, 来删除一条规则吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) num target prot opt source destination 1 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 3 INPUT_direct all -- 0.0.0.0/0 0.0.0.0/0 4 INPUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0 5 INPUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0 6 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID 7 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited ...(omitted) [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) num target prot opt source destination 1 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 3 INPUT_direct all -- 0.0.0.0/0 0.0.0.0/0 4 INPUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0 5 INPUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0 6 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID ...(omitted)
iptables的匹配和规则 基本匹配 [!] -s, –src, –source IP|Netaddr: 检查报文中的源IP地址, 加上!来进行取反.
[!] -d. –dst, –destination IP|Netaddr: 检查报文中的目的IP地址, 加上!来进行取反.
-p –protocol {tcp|udp|icmp} 检查报文中的协议, 是说IP首部中protocol所指明的那个.
-i –in-interface IFACE: 数据报文的流入接口. 仅用于PREROUTING, INPUT, FORWARD.
-o –out-interface IFACE: 数据报文的流出接口, 仅用于FORWARD, OUTPUT, POSTROUTING.
目标 使用-j TARGET来指明(jump的意思): ACCEPT接受, DROP丢弃, REJECT拒绝, RETURN返回调用链, REDIRECT端口重定向, LOG记录日志, MARK做防火墙标记, DNAT目标地址转换, SNAT源地址转换, MASQUERADE地址伪装, 还有自定义链..
至此, 我们就可以开始写简单的规则了. 下面就来试试: ( 先清空所有规则和自定义链 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 378 30392 ACCEPT tcp -- * * 0.0.0.0/0 192.168.56.103 Chain FORWARD (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 111 11776 ACCEPT tcp -- * * 192.168.56.103 0.0.0.0/0 [root@WWW ~] Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 382 30720 ACCEPT tcp -- * * 0.0.0.0/0 192.168.56.103 Chain FORWARD (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 114 12728 ACCEPT tcp -- * * 192.168.56.103 0.0.0.0/0
会发现第二次的包数量和大小增大了, 显然SSH也是符合这些规则的, 这个时候PING这台机器就不会通了:
1 2 3 4 5 6 7 8 9 10 [c:\~]$ ping 192.168.56.103 Pinging 192.168.56.103 with 32 bytes of data: Request timed out. Request timed out. Request timed out. Request timed out. Ping statistics for 192.168.56.103: Packets: Sent = 4, Received = 0, Lost = 4 (100% loss)
此时回到主机, 会发现:
1 2 3 4 5 6 7 8 9 10 11 [root@WWW ~] Chain INPUT (policy DROP 4 packets, 240 bytes) pkts bytes target prot opt in out source destination 405 32656 ACCEPT tcp -- * * 0.0.0.0/0 192.168.56.103 Chain FORWARD (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy DROP 1 packets, 76 bytes) pkts bytes target prot opt in out source destination 134 17152 ACCEPT tcp -- * * 192.168.56.103 0.0.0.0/0
DROP了4个包, 其实就是我们的ICMP包.
接着如果想要让PING能显示主机可达怎么办? 添加一条规则! 如果你是这么想的就错了, 比如:
1 2 3 4 5 6 7 8 9 10 11 12 [root@WWW ~] [c:\~]$ ping 192.168.56.103 Pinging 192.168.56.103 with 32 bytes of data: Request timed out. Request timed out. Request timed out. Request timed out. Ping statistics for 192.168.56.103: Packets: Sent = 4, Received = 0, Lost = 4 (100% loss)
为什么? 原因很简单啊, 在之前的CCNA实验中这个其实就已经说明过了, 因为我们发送的响应报文出不去, 所我们需要:
这样就可以通信了. 这样的规则虽然有用但是没有不灵活, 所以现在我们来说说扩展匹配 .
扩展匹配 扩展匹配分成两种: 隐式扩展和显示扩展. iptables有很多扩展模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 [root@WWW ~] ...(omitted) /usr/lib64/xtables/libipt_CLUSTERIP.so /usr/lib64/xtables/libipt_DNAT.so /usr/lib64/xtables/libipt_ECN.so /usr/lib64/xtables/libipt_LOG.so /usr/lib64/xtables/libipt_MASQUERADE.so /usr/lib64/xtables/libipt_MIRROR.so /usr/lib64/xtables/libipt_NETMAP.so /usr/lib64/xtables/libipt_REDIRECT.so /usr/lib64/xtables/libipt_REJECT.so /usr/lib64/xtables/libipt_SAME.so /usr/lib64/xtables/libipt_SNAT.so /usr/lib64/xtables/libipt_TTL.so /usr/lib64/xtables/libipt_ULOG.so /usr/lib64/xtables/libipt_ah.so /usr/lib64/xtables/libipt_icmp.so /usr/lib64/xtables/libipt_realm.so /usr/lib64/xtables/libipt_ttl.so /usr/lib64/xtables/libipt_unclean.so /usr/lib64/xtables/libxt_AUDIT.so /usr/lib64/xtables/libxt_CHECKSUM.so /usr/lib64/xtables/libxt_CLASSIFY.so /usr/lib64/xtables/libxt_CONNMARK.so /usr/lib64/xtables/libxt_CONNSECMARK.so /usr/lib64/xtables/libxt_CT.so /usr/lib64/xtables/libxt_DSCP.so /usr/lib64/xtables/libxt_HMARK.so /usr/lib64/xtables/libxt_IDLETIMER.so /usr/lib64/xtables/libxt_LED.so /usr/lib64/xtables/libxt_MARK.so /usr/lib64/xtables/libxt_NFLOG.so /usr/lib64/xtables/libxt_NFQUEUE.so /usr/lib64/xtables/libxt_NOTRACK.so /usr/lib64/xtables/libxt_RATEEST.so /usr/lib64/xtables/libxt_SECMARK.so /usr/lib64/xtables/libxt_SET.so /usr/lib64/xtables/libxt_SYNPROXY.so /usr/lib64/xtables/libxt_TCPMSS.so /usr/lib64/xtables/libxt_TCPOPTSTRIP.so /usr/lib64/xtables/libxt_TEE.so /usr/lib64/xtables/libxt_TOS.so /usr/lib64/xtables/libxt_TPROXY.so /usr/lib64/xtables/libxt_TRACE.so /usr/lib64/xtables/libxt_addrtype.so /usr/lib64/xtables/libxt_bpf.so /usr/lib64/xtables/libxt_cgroup.so /usr/lib64/xtables/libxt_cluster.so /usr/lib64/xtables/libxt_comment.so /usr/lib64/xtables/libxt_connbytes.so /usr/lib64/xtables/libxt_connlabel.so /usr/lib64/xtables/libxt_connlimit.so /usr/lib64/xtables/libxt_connmark.so /usr/lib64/xtables/libxt_conntrack.so /usr/lib64/xtables/libxt_cpu.so /usr/lib64/xtables/libxt_dccp.so /usr/lib64/xtables/libxt_devgroup.so /usr/lib64/xtables/libxt_dscp.so /usr/lib64/xtables/libxt_ecn.so /usr/lib64/xtables/libxt_esp.so /usr/lib64/xtables/libxt_hashlimit.so /usr/lib64/xtables/libxt_helper.so /usr/lib64/xtables/libxt_iprange.so /usr/lib64/xtables/libxt_ipvs.so /usr/lib64/xtables/libxt_length.so /usr/lib64/xtables/libxt_limit.so /usr/lib64/xtables/libxt_mac.so /usr/lib64/xtables/libxt_mark.so /usr/lib64/xtables/libxt_multiport.so /usr/lib64/xtables/libxt_nfacct.so /usr/lib64/xtables/libxt_osf.so /usr/lib64/xtables/libxt_owner.so /usr/lib64/xtables/libxt_physdev.so /usr/lib64/xtables/libxt_pkttype.so /usr/lib64/xtables/libxt_policy.so /usr/lib64/xtables/libxt_quota.so /usr/lib64/xtables/libxt_rateest.so /usr/lib64/xtables/libxt_recent.so /usr/lib64/xtables/libxt_rpfilter.so /usr/lib64/xtables/libxt_sctp.so /usr/lib64/xtables/libxt_set.so /usr/lib64/xtables/libxt_socket.so /usr/lib64/xtables/libxt_standard.so /usr/lib64/xtables/libxt_state.so /usr/lib64/xtables/libxt_statistic.so /usr/lib64/xtables/libxt_string.so /usr/lib64/xtables/libxt_tcp.so /usr/lib64/xtables/libxt_tcpmss.so /usr/lib64/xtables/libxt_time.so /usr/lib64/xtables/libxt_tos.so /usr/lib64/xtables/libxt_u32.so /usr/lib64/xtables/libxt_udp.so ...(omitted)
其中, 大写的都是TARGET, 小写的都是匹配条件. 上面就可以清晰的看到udp和tcp啦 就在这个文字的上面.
如果想要使用扩展匹配, 就需要先指定**-m**在后面加上你的match_name, 接着就是各个扩展的专用选项了. 几乎每个拓展都是这样使用的. 例如:
但是, 如果你之前已经指定了-p tcp协议, 那么-m参数是可以不用写的, 这就叫做隐式扩展 啦 而显式扩展 就是必须通过-m参数来指定的扩展.
那么我们现在就要挨个来说这些扩展的选项了.
首先是tcp的扩展. 最常用的就是端口匹配, 其中使用–dport和–sport来分别制定目的和源端口, 后面可以跟上单独的一个端口号, 也可以使用-PORT来说明一段连续 的端口.
1 2 [root@WWW ~] [root@WWW ~]
接着就可以把原来的删除掉了. 现在的状态就是只有22端口开放了, 于是我们现在开启http服务:
现在访问显然是不能访问的. 因为我们没有开启80端口的访问权限.
添加下面的规则:
1 2 [root@WWW ~] [root@WWW ~]
这样就可以看到了.
这两个选项是最多人都知道的烂大街选项, 接下来说一个大家没怎么见过的选项: 也就是–tcp-flag, 也就是ACK, SYNC, RST, FIN, PSH, URG这些, 即匹配标识字段. 这个选项的格式是这样:
--tcp-flag LIST1 LIST2
意义是这样, 检查LIST1中所指明的所有标志位, 且这其中 , LIST2所表示出的所有标志位必须为1, 其他必须为0, LIST1中没有列出的, 不做检查
实例:
1 --tcp-flags SYN,ACK,FIN,RST SYN
这是什么意思啊, 这就是匹配TCP三次握手的第一个包.(请求建立连接的那个)
上述实例 其实有一个简写: --syn.
接下来看看icmp的一个扩展选项, –icmp-type 在后面可以指定数字来表示类型, 最常见的就是0和8, 一个回送报文, 一个是请求报文.
通过这个选项, 我们就可以实现只允许我们主机去Ping别的主机, 别的主机不能Ping我们:
1 2 [root@WWW ~] [root@WWW ~]
上面就是常见的隐式扩展, 而另一个显式扩展就要复杂一点了, 我们来看看.
不过这么多拓展我们用到的也不是全部, 就从其中找一些最常使用的扩展来说吧:
multiport
我们在上面指定端口的时候, 说过只能指定连续的一段或者一个特定的端口, 这个扩展就是为了实现指定离散端口的, 使用方法如下:
1 2 3 [!] --source-ports,--sports port[,port|,port:port]... [!] --destination-ports,--dports port[,port|,port:port]... [!] --ports port[,port|,port:port]...
使用逗号来进行分割不同的端口, 使用冒号来进行端口范围声明. 我们现在所加载的规则允许Web服务和SSH服务, 但是他们是分开的, 现在加一条两者都说明的:
1 2 [root@WWW ~] [root@WWW ~]
删除旧规则, 于是我们的iptables就会变成这个样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@WWW ~] Chain INPUT (policy DROP) target prot opt source destination ACCEPT tcp -- 192.168.56.0/24 192.168.56.103 multiport dports 22,80 ACCEPT icmp -- 0.0.0.0/0 192.168.56.103 icmptype 0 Chain FORWARD (policy DROP) target prot opt source destination Chain OUTPUT (policy DROP) target prot opt source destination ACCEPT tcp -- 192.168.56.103 192.168.56.0/24 multiport sports 22,80 ACCEPT icmp -- 192.168.56.103 0.0.0.0/0 icmptype 8
这样就好看多了.
iprange
这也是一个常用拓展, 听名字也知道是干嘛的了, 一般我们只能指定网段, 但是如果遇到不是一个网段的情况就不行了, 这个时候我们就可以使用iprange来声明一段连续IP地址.
用法也很简单:
1 2 [!] --src-range from[-to] [!] --dst-range from[-to]
实例:
1 2 [root@WWW ~] [root@WWW ~]
这样就只允许前10台主机进行访问了. 很简单吧.
string
这个string扩展可以用来检查报文中出现的字符,就是说如果你没有进行加密, 那么一般来说所有的数据传输对于网络上的所有主机来说都是可以查看的, 因为所有数据包封装只是在源数据的最前面附上了一段协议头部而已. 使用这个string扩展, 我们就可以对进出的数据包进行审查, 寻找匹配我们指定的字符的数据.
使用方法就像这样:
1 2 3 4 5 6 --algo {bm|kmp} [!] --string pattern Examples: iptables -A INPUT -p tcp --dport 80 -m string --algo bm --string 'GET /index.html' -j LOG
其实还有很多选项, 只不过使用的不多. 其中算法是必须要指定的.
我们来做个实验, 在Web服务器中加上一个页面:
接着尝试访问:
没有问题, 接着我们加上这样的规则:
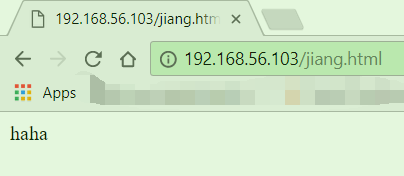
接着我们强行刷新 , 或者更换浏览器或者打开开发者模式强行不请求缓存. 你会发现被拒绝了.
但是:

没有haha的就可以正常访问.
time
什么是time扩展呢~简单的一个应用就是可以在一定的时间内开启数据传输, 其他时间不行. 可以匹配标准时间(包括年月日小时分钟秒钟), 仅仅匹配时间, 仅仅匹配星期, 可以组合使用.
这个拓展支持的选项很多:
1 2 3 4 5 6 7 --datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]] --datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]] --timestart hh:mm[:ss] --timestop hh:mm[:ss] [!] --monthdays day[,day...] [!] --weekdays day[,day...] --kerneltz
现在就来试试, 不过我们先把之前的那个haha删掉, 接着添加规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@WWW ~] [root@WWW ~] Chain INPUT (policy DROP) target prot opt source destination REJECT tcp -- 0.0.0.0/0 192.168.56.103 tcp dpt:80 TIME from 23:00:00 to 23:35:00 reject-with icmp-port-unreachable ACCEPT tcp -- 0.0.0.0/0 192.168.56.103 multiport dports 22:23,80 source IP range 192.168.56.1-192.168.56.10 Chain FORWARD (policy DROP) target prot opt source destination Chain OUTPUT (policy DROP) target prot opt source destination ACCEPT tcp -- 192.168.56.103 0.0.0.0/0 multiport sports 22:23,80 destination IP range 192.168.56.1-192.168.56.10 [root@WWW ~] Tue Oct 10 23:31:27 CST 2017
于是现在测试显然是不能访问的, 但是35之后就可以了. 这个可以自己测试.
connlimit
连接限制扩展, 可以对单个IP的并发访问限制. 使用方法也很简单.
1 2 --connlimit-upto n --connlimit-above n
upto就是<=, above就是>. 这样就允许不同的访问控制机制, 一般都是upto放行, above拒绝.
我们可以这样做一个实验, 在当前22端口放行的规则之前加一条, 只允许单IP最大2条连接:
接着我们进行连接:(在已有一条连接的基础上)
1 2 Connecting to 192.168.56.103:22... Connection established.
成功! 接着再来一条:
1 2 Connecting to 192.168.56.103:22... Could not connect to '192.168.56.103' (port 22): Connection failed.
被拒绝.
limit
这个扩展更加常用, 是对收发报文的速率做匹配.而connlimit是对连接数做匹配. 它基于令牌桶过滤器.
令牌桶是个什么玩意?
可以把它理解成是看3D小电影的时候, 每个人会发一个塑料片, 当塑料片发完了之后, 就不能再入场了(因为没有塑料片了就看不了了), 只有当前面的人看完了, 把塑料片还回来的时候才可以继续入场. 这里,每一个塑料片就是令牌. 而所有的塑料片就是令牌桶.
对于速率的控制还是挺灵活的:
1 2 --limit rate[/second|/minute|/hour|/day] --limit-burst number
上面的好说, 关于这个burst, 可以理解成是一种容忍, 一开始我不做限制, 但是当你一直在挑战底线的时候, 我就做限制. 做做实验就明白了.
我们现在试试进行Ping速率的限制, 限制到2s一个, 峰值设置成5
1 2 [root@WWW ~] [root@WWW ~]
接下来用另外一台主机做个测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@localhost ~] PING 192.168.56.103 (192.168.56.103) 56(84) bytes of data. 64 bytes from 192.168.56.103: icmp_seq=1 ttl=64 time=1.48 ms 64 bytes from 192.168.56.103: icmp_seq=2 ttl=64 time=1.21 ms 64 bytes from 192.168.56.103: icmp_seq=3 ttl=64 time=1.16 ms 64 bytes from 192.168.56.103: icmp_seq=4 ttl=64 time=1.63 ms 64 bytes from 192.168.56.103: icmp_seq=5 ttl=64 time=1.34 ms 64 bytes from 192.168.56.103: icmp_seq=6 ttl=64 time=1.25 ms 64 bytes from 192.168.56.103: icmp_seq=7 ttl=64 time=2.42 ms 64 bytes from 192.168.56.103: icmp_seq=8 ttl=64 time=2.71 ms 64 bytes from 192.168.56.103: icmp_seq=9 ttl=64 time=1.31 ms 64 bytes from 192.168.56.103: icmp_seq=11 ttl=64 time=1.71 ms 64 bytes from 192.168.56.103: icmp_seq=13 ttl=64 time=3.82 ms 64 bytes from 192.168.56.103: icmp_seq=15 ttl=64 time=1.42 ms
我们来分析一下结果, 首先前9个包很正常, 这是因为其中有2s一个的包(4个)加上我允许的5个包, 也就是4+5=9. 后面就可以理解了.
state
这个扩展是一个至关重要的扩展, 根据连接追踪机制, 可以检查连接状态. 这个追踪和TCP的挥手状态不一样, 他是iptables在内核中的一块空间, 会记录每一个连接的来源,状态和计时器. 当计时器归零的时候就会删除这个记录. 但是想想啊, 这一块记录是存在内核的内存空间的, 如果来了几百万个连接都进行记录, 一下就把内核的内存空间占掉了, 那就是个大麻烦了. 所以对于繁忙的服务器来说, 连接追踪这个功能不应该开放, 如果非要使用, 那就一定要把内核参数nd_conntrack_max调整的大一些, 否则, 一旦这一块爆了, 会造成很多严重的后果.
先来看看这个值的默认:
如果我想要知道当前在追踪哪些连接可以:
1 2 [root@WWW ~] ipv4 2 tcp 6 299 ESTABLISHED src=192.168.56.1 dst=192.168.56.103 sport=9058 dport=22 src=192.168.56.103 dst=192.168.56.1 sport=22 dport=9058 [ASSURED] mark=0 zone=0 use=2
如果你没有关闭SELINUX, 你应该还可以看到其他相关信息.
那么我们可以追踪那些状态呢?
NEW :新发出的请求, 在连接追踪模板中没有的会被认作NEW
ESTABLISHED : 连接追踪模板中失效之前的状态
RELATED : 相关的连接. 例如: ftp的命令连接和数据连接, 他们互相独立但是存在相关性.
INVALID : 无法识别的连接.
关于连接追踪, 有一种很简单的用法就是防范反弹木马, 我们22,80端口肯定是只能被动的出数据,不应该主动发出请求的, 所以我们可以做这样的规则:
而出口:
确定无误之后删除原来的规则.
于是变成了这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@WWW ~] Chain INPUT (policy DROP 8 packets, 1168 bytes) pkts bytes target prot opt in out source destination 865 72596 ACCEPT tcp -- * * 0.0.0.0/0 192.168.56.103 multiport dports 22,80 state NEW,ESTABLISHED 3 176 REJECT tcp -- * * 192.168.56.1 192.168.56.103 tcp dpt:22 144 11208 ACCEPT icmp -- * * 0.0.0.0/0 192.168.56.103 icmptype 8 limit : avg 30/min burst 5 2 168 ACCEPT icmp -- * * 0.0.0.0/0 192.168.56.103 icmptype 0 Chain FORWARD (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy DROP 4 packets, 1312 bytes) pkts bytes target prot opt in out source destination 125 15888 ACCEPT tcp -- * * 192.168.56.103 0.0.0.0/0 multiport sports 22,80 state ESTABLISHED 251 20028 ACCEPT icmp -- * * 192.168.56.103 0.0.0.0/0 icmptype 0 2 168 ACCEPT icmp -- * * 192.168.56.103 0.0.0.0/0 icmptype 8
现在访问Web服务试试吧. 也是可以的.
但是仔细看看iptables, 是不是可以优化一下呢? 其实对于出站请求而言, 只要是可以入站的, 应该是都允许放行的, 那么我们可以用一条简单的规则来覆盖上述三条:
这就是连接追踪机制的好处, 同理, 只要是ESTABLISHED的连接, 我也可以在INPUT的开头加上, 这样就不用一直向下匹配了:
但是现在还是有一些问题的, 例如: 各个协议的不同等待时间是不一样的啊, 比如http的时间肯定是比tcp的时间短的. 关于此, 可以从/proc/sys/net/netfilter/这个目录下看到关于各种设置的选项.
1 2 3 4 5 6 7 8 9 10 [root@WWW ~] nf_conntrack_acct nf_conntrack_frag6_timeout nf_conntrack_tcp_max_retrans nf_conntrack_tcp_timeout_time_wait nf_conntrack_buckets nf_conntrack_generic_timeout nf_conntrack_tcp_timeout_close nf_conntrack_tcp_timeout_unacknowledged nf_conntrack_checksum nf_conntrack_helper nf_conntrack_tcp_timeout_close_wait nf_conntrack_timestamp nf_conntrack_count nf_conntrack_icmp_timeout nf_conntrack_tcp_timeout_established nf_conntrack_udp_timeout nf_conntrack_events nf_conntrack_icmpv6_timeout nf_conntrack_tcp_timeout_fin_wait nf_conntrack_udp_timeout_stream nf_conntrack_events_retry_timeout nf_conntrack_log_invalid nf_conntrack_tcp_timeout_last_ack nf_log/ nf_conntrack_expect_max nf_conntrack_max nf_conntrack_tcp_timeout_max_retrans nf_conntrack_frag6_high_thresh nf_conntrack_tcp_be_liberal nf_conntrack_tcp_timeout_syn_recv nf_conntrack_frag6_low_thresh nf_conntrack_tcp_loose nf_conntrack_tcp_timeout_syn_sent
这个问题解决了, 那新的问题又来了. 怎么进行被动模式下FTP服务的防火墙设置?
我们知道, 被动模式的FTP是说服务端随机开放端口. 肯定不能去对特定的端口进行匹配.
其实啊, 对于FTP服务的连接追踪,显然是使用RELATED状态, 而且这个其实由一个专门的模块来做:
1 2 3 [root@WWW ~] nf_conntrack_ftp.ko ...(omitted)
这个模块就是专门用来做ftp连接追踪的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@WWW ~] filename: /lib/modules/3.10.0-514.26.2.el7.x86_64/kernel/net/netfilter/nf_conntrack_ftp.ko alias : nfct-helper-ftpalias : ip_conntrack_ftpdescription: ftp connection tracking helper author: Rusty Russell <rusty@rustcorp.com.au> license: GPL rhelversion: 7.3 srcversion: D43BF56A22E3D137BA1227B depends: nf_conntrack intree: Y vermagic: 3.10.0-514.26.2.el7.x86_64 SMP mod_unload modversions signer: CentOS Linux kernel signing key sig_key: 61:8F:5D:DF:77:2E:4B:E8:25:FB:1B:B0:95:91:86:27:24:ED:1E:97 sig_hashalgo: sha256 parm: ports:array of ushort parm: loose:bool
可能, 我是说可能, 你会需要手动装载模块:
好了, 接下来开始做这个实验.
首先我们试试在没有防火墙的时候状态怎么样, 但是这个时候我们之前写的那些规则怎么办? 可以先把他们存起来, 这样做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] [root@WWW ~] Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
好了,启动vsftpd服务, 尝试访问.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~] Connected to 192.168.56.103 (192.168.56.103). 220 Welcome to blah FTP service. Name (192.168.56.103:root): ftp 331 Please specify the password. Password: 230 Login successful. Remote system type is UNIX. Using binary mode to transfer files. ftp> cd upload 250 Directory successfully changed. ftp> ls 227 Entering Passive Mode (192,168,56,103,174,187). 150 Here comes the directory listing. -rw-rw-rw- 1 0 0 0 Sep 29 06:41 test 226 Directory send OK. ftp> get test local : test remote: test 227 Entering Passive Mode (192,168,56,103,132,29). 150 Opening BINARY mode data connection for test (0 bytes). 226 Transfer complete.
没有任何问题.
那么, 现在我们还原规则, 并且修改规则使得命令连接可以进入:
1 2 [root@WWW ~] [root@WWW ~]
接着, 只要把数据连接放行就行了, 修改第一条:
试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@localhost ~] Connected to 192.168.56.103 (192.168.56.103). 220 Welcome to blah FTP service. Name (192.168.56.103:root): ftp 331 Please specify the password. Password: 230 Login successful. Remote system type is UNIX. Using binary mode to transfer files. ftp> cd upload 250 Directory successfully changed. ftp> get test local : test remote: test 227 Entering Passive Mode (192,168,56,103,69,254). 150 Opening BINARY mode data connection for test (0 bytes). 226 Transfer complete.
没问题了.
刚刚我们不仅设置了ftp的放行规则, 而且还把保存和恢复过了一遍, 其实保存和恢复就是使用的输出重定向的方式, 那么到底输出了什么内容? 这个直接cat一下就可以了, 其实就是封装了一层的规则罢了.
firewalld 对于CentOS7, 使用了一个新的iptables的前端管理服务工具. 有基于图形的, 有基于命令行的. 这个玩意引入了一些新的机制, 面向Docker, Openstack等等一些云环境的新概念. 如果只是本机. 倒不是那么需要, 所以还是使用iptables先.
关于firewalld的相关信息, 可参考 firewalld_ibm
网络防火墙和nat实现 上面的都是在说主机防火墙, 那么现在再试着搭建一个网络防火墙试试?? 我们打开三台虚拟机, 其中一台充当网关, 另外两台处于网关服务器另一个内网网卡的子网中, 且默认网关设置成为这一台.
现在的我的网络情况是这样:
外网: CentOS6 (node2)– 外网IP: 192.168.206.131
网关: CentOS7 (localhost)– 外网IP: 192.168.206.137 内网IP: 172.16.100.254/24
内网: CentOS6 (node1)– 内网IP: 172.16.100.254
重要: 网关开启了核心转发功能, 且外网服务器加入了到内网IP的路由.
现在内网和外网主机可以随意互相访问. 如果没有请检查路由表和是否开启net.ipv4.ip_forward
接着我们在内网服务器开启http服务, 尝试用外网访问:
1 2 [root@node2 ~] <h1>It works!</h1>
好, 这很显然. 那么回到我们的主题: iptables. 我现在不希望外部主机能够进行ping我们内网的主机, 但是它能够访问Web服务.
1 2 3 [root@localhost ~] [root@localhost ~] [root@localhost ~]
这样就好了 一进一出:
测试一下:
1 2 3 4 5 6 7 8 [root@node2 ~] PING 172.16.100.10 (172.16.100.10) 56(84) bytes of data. --- 172.16.100.10 ping statistics --- 5 packets transmitted, 0 received, 100% packet loss, time 5001ms [root@node2 ~] <h1>It works!</h1>
这只是在做实验, 实际上一个网络防火墙是这样的功能才对:
1 2 [root@localhost ~] [root@localhost ~]
这就是一个比较标准的防火墙应用啦~. 其他的设定就和之前其实是很相似的, 所以可以举一反三的哦.
但是现在的配置是个有问题的配置, 我们假设外网服务器是个公网IP, 而且中间的路由器有可能很多可能是公网路由. 这样我们的内网主机是无法获得外网的响应的, 因为公网服务器得到的报文源地址是个私有地址, 路由往哪里走啊?
那么为了解决这个问题, 有什么好办法吗? 对了, 我们想到了nat和proxy. 其中, nat其实是为了隐藏本地网络的主机的(最早), 而proxy一般是在应用层实现不同于nat在网络层和传输层实现. 现在我们先说说nat.
NAT就是网络地址转换了, 现在主要有地址转换[SNAT, DNAT]和端口转换两种, SNAT和DNAT两种其实是相互对应的. 一般情况下, 我们内网的主机发起对外网的通信请求, 这些请求都会先到达网关, 这个网关服务器现在扮演的角色就是nat server. 他不监听在任何一个套接字上, 也不是一个服务或者进程, 而是内核中的一些转发规则的实现.
当报文发送到网关的时候, 源地址被改成网关的外网通信IP, 目的地址不变, 接着外网服务器的响应报文将携带着目的地址为网关服务器的外网通信IP发送回来, 于是该响应报文再次被修改成目的地址为内网IP从内网接口被发送出去.
那么问题来了, 网关服务器或者说nat server怎么知道这个报文是发给谁的? 如果内网中有很多台主机的话, 决定报文流向的机制其实就是我们说过的连接追踪机制 因为这个报文是内网主机先发送的, 所以内核中是存在追踪记录的话, 就好办了. 这样也就造成一个非常难办的问题: IP协议变成了不公平的协议. 只有内网主机才可以主动发送请求.
显然, DNAT只能运行在PREROUTING上, 而SNAT也只能运行在POSTROUTING上.
简单的说一下proxy吧. 刚刚说过了proxy是运行在应用层的, 因为网关服务器需要理解客户请求的协议到底是什么协议的, 所以报文会径直到达网关的用户空间的代理进程, 接着重新封装发向目的地址. 注意啦 这里的请求发出者就是网关, 所以不存在什么转换的问题. 接着同样服务器也会把响应报文径直发向代理服务器(网关服务器), 接着代理进程重新封装报文发送给客户. 就是这样的过程.
现在切入正题, 来使用iptables实现nat功能. 我们在外网服务器开启httpd服务, 清空三台主机所有的iptables规则, 并且在内网主机配置默认路由, 设置网关. 现在我想做的事情是在网关服务器配置一条nat规则, 将内网的主机源地址转换成为网关的IP地址.
在做这个事情之前我们先在外网服务器加上一条能够到达内网服务器的路由:
接着内网请求Web服务:
1 2 [root@node1 ~] <h1>Test</h1>
于是我们可以在外网的访问日志中看到:
1 172.16.100.10 - - [12/Oct/2017:14:04:15 +0800] "GET / HTTP/1.1" 200 14 "-" "curl/7.19.7 (x86_64-unknown-linux-gnu) libcurl/7.19.7 NSS/3.12.7.0 zlib/1.2.3 libidn/1.18 libssh2/1.2.2"
来源IP是172.16.100.10, 好的. 删除刚才添加的路由. 这个时候就不能互相通信了.
那么, 现在就来进行转换:
简单的说明一下吧, SNAT就是target了, 后面的参数就是将源地址改成192.168.206.137的意思了.
现在再进行访问:
1 2 [root@node1 ~] <h1>Test</h1>
同时我们检查日志:
1 192.168.206.137 - - [12/Oct/2017:14:34:39 +0800] "GET / HTTP/1.1" 200 14 "-" "curl/7.19.7 (x86_64-unknown-linux-gnu) libcurl/7.19.7 NSS/3.12.7.0 zlib/1.2.3 libidn/1.18 libssh2/1.2.2"
来自192.168.206.137的访问记录~成功了. 那么现在再来玩一个, 我们把他们翻转过来, 内网服务器开Web服务, 然后外网服务器去访问, 由于内网IP是私有的, 所以对于外网服务器而言, 他只能去访问网关的那个公网IP, 但是我们知道网关是没有开启80端口的. 那么我们就需要将发往网关服务器的80端口的请求转换成访问内网的IP这样的一个操作.
在添加此条规则之前:
1 2 [root@node2 ~] curl: (7) couldn't connect to host
在添加之后我们就可以看到:
1 2 [root@node2 ~] <h1>It works!</h1>
需要再次说明的是, 137上没有开启httpd服务, 80端口也没有进程在监听.
同理, 我们也可以进行端口映射, 如果内网Web服务的监听端口不在80, 就映射到那个端口就好了. 很简单了.
DNAT没什么了, 回到SNAT, 考虑这样的一个问题. 有些网关的网络地址并不一定是固定的, 他有可能随着拨号的不同会有不同的IP, 面对这样的情况难道我们要每一次修改一次–to-source吗? 显然不能, 这个时候就需要进行来源地址伪装, 即MASQUERADE
假设现在我们的网关地址变了, 那么内网主机就不能访问外网服务器了:
1 2 [root@localhost ~] [root@localhost ~]
在这种情况下, 由于配置了下面的项目:
我们的内网主机依然可以访问外网Web服务.
TCP_wrapper 最后我们再简单说说TCP_wrapper这个玩意. 这是一个基于tcp协议开发并提供服务的应用程序, 提供一层访问控制的工具, 基于库调用实现功能. – libwrap
那么我们怎么知道哪些服务可以用tcp_wrapper实现控制呢?
我们知道在编译的时候, 如果使用到共享库, 那么有两种方式: 一种是进行链接, 一种是进行静态编译,即编译进程序. 对于动态的好办,直接ldd就行了. 而静态的就稍微麻烦一点: 我们要使用strings查看应用程序, 如果出现hosts.allow和hosts.deny就是可以的.
比如现在试试sshd和vsftpd:
1 2 3 4 5 6 7 8 9 10 [root@localhost ~] linux-vdso.so.1 => (0x00007fff325a1000) libfipscheck.so.1 => /lib64/libfipscheck.so.1 (0x00007ff6d2088000) libwrap.so.0 => /lib64/libwrap.so.0 (0x00007ff6d1e7d000) ...(omitted) [root@localhost ~] linux-vdso.so.1 => (0x00007fffb97ca000) libssl.so.10 => /lib64/libssl.so.10 (0x00007ff14f6c7000) libwrap.so.0 => /lib64/libwrap.so.0 (0x00007ff14f4bc000) ...(omitted)
而httpd就不可以.
使用tcp_wrapper来做访问控制要比iptables简单多了, 只要编辑/etc/hosts.deny和/etc/hosts.allow就可以了.
配置文件的语法格式就是:
1 daemon_list: client_list [:options]
听名字也知道allow就是白名单, deny就是黑名单. 那么如果我两个文件里都写了, 怎么样呢? 其实是有匹配次序的, 优先匹配allow, 如果有则直接放行, 如果没有则匹配deny, 如果有则拒绝, 没有则默认策略放行.
这里的daemon_list一定是文件名称, 不能是服务名, 多个可以使用逗号分隔:
1 sshd, vsftpd: 172.16.0.0/255.255.0.0|ALL|KNOWN|UNKNOWN|PARANOID
另外, 对于client_list, 可以在后面加上EXCEPT关键字:
EXCEPT: 除了. 这个选项还可以连续使用两次 双重否定 = 肯定
现在就直接试试吧:
先用另外一台主机访问sshd服务:
1 2 3 4 5 [root@node2 ~] root@192.168.206.133's password: Last login: Thu Oct 12 15:49:50 2017 from 192.168.206.131 [root@localhost ~]# logout Connection to 192.168.206.133 closed.
接着编辑:
1 2 [root@localhost ~] sshd: 192.168.206.131
接着:
1 2 [root@node2 ~] ssh_exchange_identification: Connection closed by remote host
很简单吧.
接着我们看一下后面的选项有哪些:
deny: 在allow中使用
allow: 在deny中使用.
spawn: 启动额外程序, 例如
1 2 vsftpd: ALL :spawn /bin/echo `date ` login attempt from %c to %s ,%d >> /var/log/vsftpd.deny.log
这里的%c: client IP; %s: server IP; %d: daemon name
17-10-13的更新:
在书上看到了关于iptables的案例, 在这里说一说: 案例是说用户使用公网传输文件正常, 但是使用自建GRE VPN大内网只能传输2Kb大小文件, 停止iptables之后可以传输大文件. 而且在开启iptables之后的10分钟内, 可以继续传输大文件, 10分钟后传输被卡住.
通过抓包, 发现出现了下面的情况: ICMP Destination unreachable (Fragmentation needed)
而iptables对ICMP的设定和我们之前设定的是一样的:
1 2 iptables -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT
所以说, GRE封装的24字节(GRE报文+IP包头)在默认的1500中减去, 网关的MTU应该是1476才对. 但是这个案例中网络管理员将路由器的MTU设置成为了1400, 而协商MTU的ICMP报文又无法到达, 导致协商失败.
为什么10分钟之内可以呢? 因为存在一个叫做PMTU的东西, 这个叫做两台通信主机之间最小的MTU, 即路径MTU. 默认的老化时间就是10分钟.
之前所说的ICMP协商MTU, 这个被叫做路径最大传输单元发现, PMTUD.
为了解决问题, 添加规则:
1 iptables -A INPUT -p icmp --icmp-type fragmentation-needed -j ACCEPT