打开高可用的探索之门~
高可用集群基础 我们已经了解了LB集群的实现, 使用了lvs, nginx, haproxy等等. 其实这些服务或者功能都十分轻量. 但是director作为整个系统的单点所在, 我们需要考虑下对这个调度器做高可用 (HA).
但是高可用的架构有很多, 例如今天要说的keepalived, 还有heartbeat, corosync, cman等等. 这些中最为轻量的就是这个keepalived. 在这样的场景下, 真心没有必要去使用后面的那些. 所以 我们选择使用keepalived来构建这么一个小型的高可用集群. 事实上 keepalived原本设计的面向就是为了LVS实现的高可用解决方案. 只不过现在他已经拓展了很多功能了, 通过外置脚本和插件的形式, 只不过在配置文件中, keepalived原本就已经支持对LVS的种种高可用操作. 所以十分适合. 至于后面那些, 都是为了10几个, 几百个这样的大型服务器集群.
在高可用的场景中, 我们经常会将一个节点做双份, 这个时候我们把正在使用的那一个定义成**active的, 而冗余的那一台就是 passive**的, 也可以叫做backup节点. 回到那个问题, 备用节点怎么得知活动节点服务出现问题, 并且通过什么方式来取代其作为服务. 现在我们就很好回答这个问题了, 只要两个或者多个节点都有相同的服务, 例如我们的LVS, 一个director需要一个VIP和ipvs规则才可以, 在例如我们的nginx, 他也需要一个VIP和自己的nginx服务, 再如haproxy, 还是需要一个VIP和自己的服务配置. 那么也就是说, 从节点需要获得和主节点一样的IP, 一样的服务配置或者规则.
但是, 以现在的认知, 两个节点拥有同一个IP地址似乎是存在问题的. 先不管这个, 一个主机想要作为负载均衡调度的节点的话, 是需要我们上面 说的那些的, 我们把这个东西称作资源(resource) , 高可用集群中的资源. 所以一个高可用集群中最珍贵的资源就是我们的VIP了.
那么, 如果当发现主节点出现问题, 从节点将IP配置上, 这个时候我们漏掉了一个很重要的部分的, 存储 .我们说过存储的数据分两种, 结构化数据和非结构化数据. 结构化的数据都是存储在数据库中的, 数据库对于并发控制是存在的, 所以我们也先不考虑这个, 问题在于非结构化数据, 如果是挂载的共享存储, 这个时候两台节点都有进程都在对文件系统进读写, 我们知道Linux对于文件系统的数据读写是在内存中完成的, 这样在并发的情况下就会出现大量脏数据的情况, 导致结果不一致, 从而使得数据损坏. 除了共享存储, 我们也可以使用同步, 不过仅仅适合于数据量很少的情况.
这个时候, 我们就需要分布式存储的协力, 或者支持并发访问的文件系统了. 所以, 我们现在稍作总结, 在这样的高可用场景中, 最重要的资源就是IP和存储了, 至于服务, 我们只要运行相同, 配置文件也保持一致就行了.
接着在回到之前说的配置IP这一点上, 如果直接就这么配置上, 一个明显的问题就是我们director之前的路由器就傻了, 可能会出现一段时间是第一台节点, 一段时间路由到第二台节点的情况. 这怎么办呢? 很简单了, 只要确保必须是一台活动, 一台备用就行了, 也就是说只要一台得到了IP, 另外一台就不能进行工作. 这样的话就回到了那个老话题 – 如何判断主备状态.
监控, 对. 显然, 监控就可以解决问题. 但是监控也是分很多形式的, 比如可以一问一答, 也可以进行单方向发送状态信息. 一般情况下, 我们选择的方式是后者. 而且还是基于组播的发送. 另外, 这个机制的一个重要的考量因素就是时间 . 主机之间的时间必须同步. 否则极大几率会出现误判. 那么如何实现时间同步? 简单, 只要指向同一台ntp服务器就行了. 我不管这个时间是否准确, 只要你们的 时间一样就行了.
要说到keepalived, 首先我们要说说vrrp, 也就是虚拟路由冗余协议.
keepalived和vrrp简述 网络工程师肯定是很熟悉这个vrrp了, 在华为, H3C, Cisco都有相关的技术文档. 事实上vrrp的工作原理和上面说的那些差不多了, 作为网关的路由器可以说是很重要的设备, 所以为了后端服务器的高可用, 我们会对网关进行一个冗余, 只要正在运行的, 也就是active的路由设备一直向冗余的路由设备发送心跳, 就认定成是可用的, 一段周期内, 备份的路由器如果没有心跳数据包, 就会取代这个网关路由, 保持这个通道的连续和可靠.
那么vrrp怎么工作的? 核心的思想就是将两个路由器构建成一个或者多个虚拟路由. 具体的实施过程是这样的, 首先, 配置成虚拟路由的多台路由器之间协商, 选举出一台Master节点, 选举主要依靠他们的优先级, 如果优先级相同, IP地址大的成为Master. 接着, Master路由周期性的发送vrrp报文, 通报自己的配置信息和工作状态. 如果Master路由出现故障, 剩余的Backup路由重新进行选举出新的Master, 并且发布一个携带虚拟IP和自己的虚拟MAC地址的免费ARP报文从而更新网络中的ARP信息. 这里的ARP报文也可以理解成是ARP欺骗.
当然直接这样发送报文, 不是这么的安全, 所以vrrp也支持认证功能. 包括简单的字符认证, 和MD5认证. 不过对于一个频繁发送的心跳包来说, MD5计算显然是一个很消耗性能和带宽的方式. 所以一般都会选择简单的字符认证.
另外, 考虑到backup路由一直处于闲置的状态, 我们可以构建双主模型 . 就是说, R1和R2两台路由器, 我们可以配置两个虚拟路由器, 其中一个R1做主, 另一个R2做主. 这样还可以实现负载均衡, 还充分运用了资源.
keepalived就是对vrrp协议在Linux主机上的以守护进程的方式的一种实现. 能够根据配置文件自动生成ipvs规则, 并且可以对各个RS做健康状态检测.
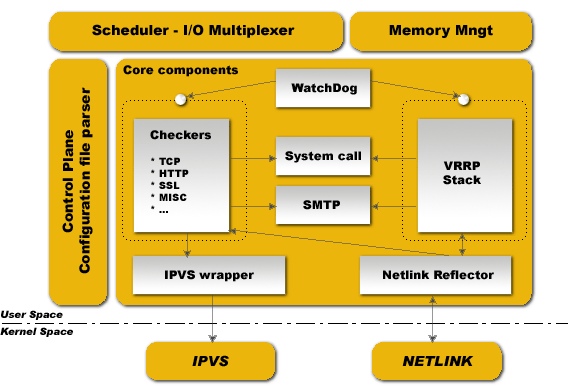
上图就是keepalived官方的一张架构图. 可以很清楚的看到, 核心组件就是那个VRRP stack了.
keepalived配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@VM-node1 ~] Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile ...(omitted) Available Packages Name : keepalived Arch : x86_64 Version : 1.3.5 Release : 1.el7 Size : 327 k Repo : base/7/x86_64 Summary : Load balancer and high availability service URL : http://www.keepalived.org/ License : GPLv2+ Description : Keepalived provides simple and robust facilities for load balancing : and high availability. The load balancing framework relies on the : well-known and widely used Linux Virtual Server (IPVS) kernel module : providing layer-4 (transport layer) load balancing. Keepalived : implements a set of checkers to dynamically and adaptively maintain : and manage a load balanced server pool according their health. : Keepalived also implements the Virtual Router Redundancy Protocol : (VRRPv2) to achieve high availability with director failover.
安装就直接yum install就行了.
来看看安装了那些东西吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 root@VM-node1 ~] /etc/keepalived /etc/keepalived/keepalived.conf /etc/sysconfig/keepalived /usr/bin/genhash /usr/lib/systemd/system/keepalived.service /usr/libexec/keepalived /usr/sbin/keepalived /usr/share/doc/keepalived-1.3.5 /usr/share/doc/keepalived-1.3.5/AUTHOR /usr/share/doc/keepalived-1.3.5/CONTRIBUTORS /usr/share/doc/keepalived-1.3.5/COPYING /usr/share/doc/keepalived-1.3.5/ChangeLog /usr/share/doc/keepalived-1.3.5/NOTE_vrrp_vmac.txt /usr/share/doc/keepalived-1.3.5/README /usr/share/doc/keepalived-1.3.5/TODO /usr/share/doc/keepalived-1.3.5/keepalived.conf.SYNOPSIS /usr/share/doc/keepalived-1.3.5/samples /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.HTTP_GET.port /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.IPv6 /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.SMTP_CHECK /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.SSL_GET /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.fwmark /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.inhibit /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.misc_check /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.misc_check_arg /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.quorum /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.sample /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.status_code /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.track_interface /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.virtual_server_group /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.virtualhost /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.localcheck /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.lvs_syncd /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.routes /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.rules /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.scripts /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.static_ipaddress /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.sync /usr/share/doc/keepalived-1.3.5/samples/sample.misccheck.smbcheck.sh /usr/share/man/man1/genhash.1.gz /usr/share/man/man5/keepalived.conf.5.gz /usr/share/man/man8/keepalived.8.gz /usr/share/snmp/mibs/KEEPALIVED-MIB.txt /usr/share/snmp/mibs/VRRP-MIB.txt /usr/share/snmp/mibs/VRRPv3-MIB.txt
也很简洁, 直接看看他的配置文件吧:
1 2 3 4 5 6 7 8 9 10 11 12 [root@VM-node1 ~] ! Configuration File for keepalived global_defs { } vrrp_instance VI_1 { } virtual_server 192.168.200.100 443 { } virtual_server 10.10.10.2 1358 { } virtual_server 10.10.10.3 1358 { }
也就是全局配置 接着是vrrp相关配置, 接着就是和LVS相关的vs设定.
其中vrrp的配置主要分成两个部分, 一个是vrrp实例的设定, 一个是vrrp同步组的设定. 在上面的生成的文件列表中, 可以看到还有很多配置文件的示例.
现在我们先来说几个HA集群的配置的前提:
本机主机名要和hostname以及uname -r保持一致, 并且各个节点需要能够互相解析主机名, 建议使用hosts文件进行解析.
各个节点的时间同步
这里我们使用两台CentOS7主机, 首先我们Check一下时间:
1 2 3 [root@VM-node1 ~] Fri Oct 20 18:43:55 CST 2017 Fri Oct 20 18:43:55 CST 2017
没有问题, 是同步的.
接着检查hosts文件 ( 这一步骤对于keepalived来说没这么重要 )
1 2 3 4 5 [root@VM-node1 ~] 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.206.9 VM-node1 192.168.206.21 VM-node2
接着我们要确保iptables和SELinux不会成为阻碍.
1 2 3 4 5 [root@VM-node1 ~] Enforcing [root@VM-node1 ~] [root@VM-node1 ~] [root@VM-node1 ~]
双节点安装keepalived.
好了, 准备的差不多了. 开始吧~
开始编辑配置文件, 先不使用后面的virtual server, 我们来看看前面的两个部分:
1 2 [root@VM-node1 ~] (In-Vim):.,$s /^/
从第一个全局配置来看:
1 2 3 4 5 6 7 8 9 10 11 12 13 global_defs { notification_email { root@localhost } notification_email_from kaadmin@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node1 vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 }
其实还有很多配置, 在man手册中可以看到. 我们就先这样, 主要是下面的设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass } virtual_ipaddress { 192.168.206.100/24 dev eth0 label ens33:0 } }
对于vrrp实例的配置, 我们来看看.
首先是state, 该选项的意思是初始状态标记. 后面的interface标识接口也就是VIP的绑定位置. 接着后面的virtual_router_id 该ID就比较重要了, 因为这个玩意首先是作为虚拟MAC的末尾那一位 ( 虚拟MAC的前几位是固定的00-00-5E-00-01-{VRID} ) 所以是需要保持一致的, 再往后的priority标识优先级, 越大的越高. advert_int通告的发送时间间隔. 后面的一个上下文环境是进行认证的, 类型有字符认证和md5认证, 这里使用的是简单的字符认证. 后面的虚拟IP也就是比较重要的了. 其实这里指定的就是我们的VIP. 默认使用的是抢占模式, 如果不想使用抢占模式, 那么可以指定nopreempt.
我最后修改完成的配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 1 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b5 } virtual_ipaddress { 192.168.206.100/24 dev eth0 label ens33:0 } }
其中, 随机字串是使用openssl输出的. OK, 接下来把配置文件拷贝到第二台主机上.
备用节点需要做稍微的修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 1 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b5 } virtual_ipaddress { 192.168.206.100/24 dev ens33 label ens33:0 } }
接下来, 启动服务吧!
查看一下进程和接口:
1 2 3 4 [root@VM-node2 ~] root 3092 0.0 0.1 120740 1408 ? Ss 19:32 0:00 /usr/sbin/keepalived -D root 3093 0.0 0.2 120740 2764 ? S 19:32 0:00 /usr/sbin/keepalived -D root 3094 0.0 0.2 125104 2660 ? S 19:32 0:00 /usr/sbin/keepalived -D
在node1上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@VM-node1 ~] ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.9 netmask 255.255.255.0 broadcast 192.168.206.255 inet6 fe80::1c:8a20:479a:ddc0 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:b0:97:f6 txqueuelen 1000 (Ethernet) RX packets 116014 bytes 20485653 (19.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 144513 bytes 10838375 (10.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.100 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:b0:97:f6 txqueuelen 1000 (Ethernet)
而在node2上, 你是看不到的. 为什么? 因为node2是从节点啊~
这个时候 我们手动关闭node1的keepalived服务, 接着立即去node2查看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@VM-node2 ~] ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.21 netmask 255.255.255.0 broadcast 192.168.206.255 inet6 fe80::1c:8a20:479a:ddc0 prefixlen 64 scopeid 0x20<link > inet6 fe80::2e92:22f5:af33:2394 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:71:99:af txqueuelen 1000 (Ethernet) RX packets 88514 bytes 14361599 (13.6 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 70290 bytes 5571477 (5.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.100 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:71:99:af txqueuelen 1000 (Ethernet)
从passive变成了active了. 然而, 当我们重新恢复node1的服务的时候, 由于默认是抢占模式, 所以node1就重新变成active状态了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@VM-node1 ~] [root@VM-node1 ~] ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.9 netmask 255.255.255.0 broadcast 192.168.206.255 inet6 fe80::1c:8a20:479a:ddc0 prefixlen 64 scopeid 0x20<link > ether 00:0c:29:b0:97:f6 txqueuelen 1000 (Ethernet) RX packets 116439 bytes 20524771 (19.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 145291 bytes 10898289 (10.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.206.100 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:b0:97:f6 txqueuelen 1000 (Ethernet)
但是有的时候, 我们希望能够进行服务的升级, 所以就需要让主服务器暂时成为从的, 升级之后, 再成为主的, 升级从服务器. 这个时候我就需要平滑的修改主从服务器的优先级, 而vrrp脚本功能就能满足我们的需求, 来看一个示例:
1 2 3 4 5 6 7 8 9 10 11 12 vrrp_script chk_maintenance { script "[[ -f /etc/keepalived/mt ]] && exit 0 || exit 1" interval 1 weight -2 } vrrp_instance VI_1 { ...(omitted) track_script { chk_maintenance } }
只要脚本返回值不是0, 就会执行下面的操作, 也就是将权重-2, 接着在实例中启动这个脚本.
在这里插一句, 首先新版本似乎不支持这种方式了, 仅允许在这里指定文件系统中的脚本路径. 第二, 不知道是我的操作有问题还是这个版本的keepalived有Bug(当然我觉得还是我的问题), 当我每次重启动keepalived的时候, 首次执行就会判定脚本执行成功, 于是执行下面的语句调整, 接着就一直正常执行, 但是这个时候我们的优先级是调整过的了, 所以说, 当我们把文件创建的时候, 反而会将减少的优先级加出来 ( 也就是说脚本的功能完全发生了相反的效果??. ) 于是我就在这里debug了很长时间. 还是不知道是怎么回事. 烦死了
就先当做keepalived没有这个功能吧. 继续往后.
于是不甘于失败的我又进行了尝试. 结论是: 脚本失败的时候, 会执行后面的指令. 如果脚本执行成功就不会触发. 所以上面的结论没要毛病, 所以完完全全是我的错, 所以我真的好气哦, 所以上面的脚本写反了 应该是"[[ -f /etc/keepalived/mt ]] && exit 1 || exit 0" ( 耽误了好多时间烦死了 )
行吧, 这样我们只要在指定的地方touch一个mt就可以实现主从切换了.
接下来来看一下同步组的设定. 我们知道当VIP发生改变的时候, 必须把后面接口的DIP也做转交, 这两个过程是同步的, 所以就需要绑定成组. 方法很简单, 只要使用:
1 2 3 4 vrrp_sync_group VG_1 { VI_1 VI_2 }
就行了, 同样这个也有一些选项的. 不过就先不说了.
接着我们看一下发生状态了之后 怎么进行通知呢? 我们发现, 当刚刚做实验得时候 好像没有出现接收到邮件的情况. 这是以为, 邮件的发送是需要我们自行定义邮件内容和发送脚本的.
具体的定制选项在这里: ( 可以在vrrp实例和同步组中定义 )
1 2 3 notify_master "PATH/TO/SCRIPT master" notify_backup "PATH/TO/SCRIPT backup" notify_fault "PATH/TO/SCRIPT fault"
一个典型的脚本实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #!/bin/bash vip=192.168.206.100 contact="root@localhost" notify mailsubject="`hostname` to be $1 : $vip floating." mailbody="`date '+%F %H:%M:%S'` : vrrp transition, `hostname` changed to be $1 " echo $mailbody | mail -s "$mailsubject " $contact } case "$1 " in master) notify master exit 0 ;; backup) notify backup exit 0 ;; fault) notify fault exit 0 ;; *) echo "Usage: `basename $0 ` {master|backup|fault}" exit 1 ;; esac
但是到现在为止, 我们都只是在玩玩而已, 还没有发挥keepalived作为LVS的高可用功能. 所以现在就来看下关于LVS的设定吧.
在manual中, LVS的设定都用virtual server这个关键字来说明, 可以使用IP地址, 也可以使用防火墙标记.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 delay_loop <INT> lb_algo rr|wrr|lc|wlc|lblc|sh|dh ops lb_kind NAT|DR|TUN persistence_timeout [<INT>] protocol TCP|UDP|SCTP ha_suspend virtualhost <STRING> sorry_server <IPADDR> <PORT> real_server <IPADDR> <PORT> { weight <INT> inhibit_on_failure notify_up <STRING>|<QUOTED-STRING> notify_down <STRING>|<QUOTED-STRING> uthreshold <INTEGER> lthreshold <INTEGER> HTTP_GET|SSL_GET { url { path <STRING> digest <STRING> status_code <INT> } nb_get_retry <INT> delay_before_retry <INT> }
接下来我们再看看TCP的健康检查:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 TCP_CHECK { connect_ip <IP ADDRESS> connect_port <PORT> bindto <IP ADDRESS> bind_port <PORT> connect_timeout <INTEGER> ...(omitted) }
基本上我们也就使用这两种了.
项目: LVS + keepalived实现基础高可用 我们一共开启四台虚拟机, 首先做director的有两台, 一台主节点, 一台做备份. 另外两台后端real server跑Web服务(httpd).
他们的IP分别是:
1 2 3 4 5 VIP: 192.168.206.11 DIP1: 192.168.206.9 DIP2: 192.168.206.10 RIP1: 192.168.206.22 RIP2: 192.168.206.23
哦 对了,这里我们选择使用DR集群.
先来确保需要使用的软件包存在: httpd, ipvsadm(不是必须的,仅仅是为了观察实验效果), keepalived, mailx.
接着先配置director的VIP, real server的内核参数, 添加VIP, 添加路由, 添加ipvs规则. 现在是很熟练了.
好了, 现在我们的第一个director就没问题了, 接着我们把规则清空, IP拿掉. 进入另外一个director, 进行同样的配置, 进行测试, 如果没有问题的话, 我们就可以进行配置sorry server了, 对于两个director, 安装httpd, 写入一个sorry页面, 并且启动服务.
1 2 [root@VM-node2 ~] [root@VM-node2 ~]
好了, 主角上场了, 我们最后的配置是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 ! Configuration File for keepalived global_defs { notification_email { root@127.0.0.1 } notification_email_from kaadmin@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script chk_maintenance { script /etc/keepalived/chk_maintenance interval 1 weight -5 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 1 priority 98 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b5 } virtual_ipaddress { 192.168.206.11/32 dev ens33 label ens33:0 } track_script { chk_maintenance } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" } virtual_server 192.168.206.11 80 { delay_loop 6 lb_algo wrr lb_kind DR protocol TCP real_server 192.168.206.22 80 { weight 1 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 192.168.206.23 80 { weight 2 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }
把这份配置复制连同脚本拷贝到另一个director上, 并且稍作修改.
激动人心的时候到来了! 启动服务
尝试访问, 成功了! 我们的ipvs规则, 自动的被填充了.
访问效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>It works! (From node3)</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>It works! (From node3)</h1>
好, 现在我们把其中一个real server下线:
1 2 [root@VM-node3 ~] Stopping httpd: [ OK ]
这个时候连规则都会进行重写:
1 2 3 4 5 6 [root@VM-node1 ~] IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.206.11:80 wrr -> 192.168.206.23:80 Route 2 0 3
访问自然是没有问题的.
同时维护第一台主机也是可以的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@VM-node1 ~] [root@VM-node1 keepalived] [root@VM-node1 keepalived] 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link /loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link /ether 00:0c:29:b0:97:f6 brd ff:ff:ff:ff:ff:ff inet 192.168.206.9/24 brd 192.168.206.255 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::1c:8a20:479a:ddc0/64 scope link valid_lft forever preferred_lft forever
这个是就是第二台从节点顶替上来了.
1 2 3 4 5 6 7 C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1>
访问仍然正常. 最后我们加上sorry_server的设定
1 2 3 4 5 virtual_server 192.168.206.11 80 { ...(omitted) sorry_server 127.0.0.1 80 real_server 192.168.206.22 80 { ...(omitted)
两边都做一样的设定, 接着我们重启服务之后将两个real server都手动关闭服务.
1 2 3 C:\Users\lenovo λ curl 192.168.206.11 Sorry, under maintenance
同时, 我们的调度规则也发生改变.
1 2 3 4 5 6 [root@VM-node1 keepalived] IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.206.11:80 wrr -> 127.0.0.1:80 Route 1 0 0
就是这样的一个过程.
中途关于邮件我一直没有提到, 其实会在实验中一直受到邮件的, 当然了, 前提是你要安装邮件程序包.
接下来把两台的服务开起来, 瞬间复活~.
项目: Nginx + keepalived实现基础高可用 首先, 我们很清楚了, Nginx是不需要real server的, 他需要的是upstream server就行了. 所以我们要先把之前的操作, 也就是那些IP地址删除, 路由删除, 内核参数还原.
好了 环境恢复了之后, 安装必要的软件包: Nginx.
开始配置Nginx的上游服务器组和调度, 这也是很熟练了的.
尝试访问, 是正常的就可以继续了. nginx和keepalived的基础高可用是很简单的.
这里, 由于我们不需要ipvs, 所以不需要virtual server了, 可以全部注释掉:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vrrp_script chk_nginx { script /etc/keepalived/chk_nginx interval 1 weight -10 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 1 priority 98 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b5 } virtual_ipaddress { 192.168.206.11/24 dev ens33 label ens33:0 } track_script { chk_maintenance } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
这里使用的脚本也很简单, 你也可以添加更复杂的机制. 主要的原理就是想nginx发送0号信号, 如果返回值不是0, 就说明nginx存活. 这样我们连exit语句也可以省略:
1 2 3 [root@VM-node1 keepalived] $(killall -0 nginx)
接下来启动keepalived服务吧. 访问是正常的:
1 2 3 4 5 6 7 8 9 10 11 C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>It works! (From node3)</h1>
然而, 当我们关闭主节点的nginx服务的时候:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@VM-node1 keepalived] [root@VM-node1 keepalived] 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link /loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link /ether 00:0c:29:b0:97:f6 brd ff:ff:ff:ff:ff:ff inet 192.168.206.9/24 brd 192.168.206.255 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::1c:8a20:479a:ddc0/64 scope link valid_lft forever preferred_lft forever You have new mail in /var/spool/mail/root
继续访问:
1 2 3 4 5 6 7 8 9 10 11 C:\Users\lenovo λ curl 192.168.206.11 <h1>web on Node4</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>It works! (From node3)</h1> C:\Users\lenovo λ curl 192.168.206.11 <h1>It works! (From node3)</h1>
仍然没有问题. VIP也已经转交给了次节点:
1 2 3 4 5 6 Oct 21 11:49:04 VM-node2 Keepalived_vrrp[68777]: VRRP_Script(chk_maintenance) succeeded Oct 21 11:50:11 VM-node2 Keepalived_vrrp[68777]: VRRP_Instance(VI_1) forcing a new MASTER election Oct 21 11:50:12 VM-node2 Keepalived_vrrp[68777]: VRRP_Instance(VI_1) Transition to MASTER STATE Oct 21 11:50:13 VM-node2 Keepalived_vrrp[68777]: VRRP_Instance(VI_1) Entering MASTER STATE Oct 21 11:50:13 VM-node2 Keepalived_vrrp[68777]: VRRP_Instance(VI_1) setting protocol iptable drop rule Oct 21 11:50:13 VM-node2 Keepalived_vrrp[68777]: VRRP_Instance(VI_1) setting protocol VIPs.
但是这样其实有个问题的. 想一下, 如果我们两边的Nginx服务都死了. 于是双方的weight都下降最后还是没有区别啊, 所以, 这样的一种解决方案就是在notify脚本中添加当状态发生改变的时候自动重启Nginx服务. 但是这很强硬, 有点太粗糙了.
不过起码可用.
接下来我们玩一个好玩的, 我们继续Nginx+Keepalived的组合, 组建一个双主模型的高可用集群.
首先当然我们需要两个vrrp实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 vrrp_script chk_nginx { script /etc/keepalived/chk_nginx interval 1 weight -10 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 1 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b5 } virtual_ipaddress { 192.168.206.11/24 dev ens33 label ens33:0 } track_script { chk_nginx } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" } vrrp_instance VI_2 { state BACKUP interface ens33 virtual_router_id 2 priority 98 advert_int 1 authentication { auth_type PASS auth_pass 700c8be7b50 } virtual_ipaddress { 192.168.206.12/24 dev ens33 label ens33:0 } track_script { chk_nginx } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
一个做主, 一个做备. 另外一个节点也是如此, 只不过主备颠倒. 这样就可以实现一个双主的模型.