面试的时候提到了关于HTTP协议的发展变化, 没答出来. 只记得之前在一些公众号文章中瞥过几眼, 现在来做个总结~
万维网发明 - HTTP/0.9
这玩意就真的算是HTTP协议的祖宗了, 这个也叫做单行(one-line)协议. 他是和HTML, 浏览器, 服务器(httpd的前身)一起诞生的. 而这四个部分其实就构成了我们熟知的万维网.
那么这个协议既然是最初的, 相比很简单了. 那么有多简单呢?
1 | GET /index.html |
没了.
没有MIME信息, 没有长连接, 没有缓存, 没有cookie等等HTTP头部信息. 那么作为他的响应也很简单:
1 | <HTML> |
除此之外, 客户端和服务端均使用ASCII流通信, 当文档传输结束之后, 连接就会被关闭. 有意思的是, 这个HTTP 0.9是个可以使用telnet的协议, 你可以尝试一下:
1 | telnet google.com 80 |
接着就可以看到HTTP响应了, 只不过是使用的1.0版本的:

而且能看到, 我们的连接直接中断了. 由此我们可以稍微总结一下HTTP/0.9的一些特点:
- 只支持纯文本
- 传输结束之后关闭连接
- 无状态. (HTTP的无状态性的特点从一开始就有了)
那么你可能好奇如果出错怎么办, 其实很简单, 返回一个描述错误信息的HTML.
构建可扩展性 - HTTP/1.0
随着浏览器和服务器的迅速发展, 包括HTML标准的更新, 而HTTP0.9的协议成为发展门槛, 因此人们渴求一个不单单发送超文本文档, 还可以提供更加丰富资源类型的请求和响应, 以及内容协商的协议. 因此在1996年成立了HTTP-WG(Working Group), 于是推出了一个草案版本.
从这里开始, 我们需要在请求资源的后面加上协议版本了, 并且从这里开始引入了HTTP头的概念, 我们在发送请求的时候加上User-Agent了, 并且响应结果也得到了极大地信息补足, 一个典型的请求响应就像这样:
1 | GET /index.html |
可以看到, 我们的响应头部中增加了Content-Type, 这意味着我们可以传输纯文本之外其他类型文档的能力了.
其实HTTP/1.0最具突破性的更新就是引入了HTTP头部, 有了这一段数据区, HTTP被赋予了巨大的可扩展性, 协议变得非常灵活.
在返回的头部中, 我们还可以看到一些Expires, Last-Modified关于缓存的设计了, 并且我们在响应开始时发送了状态码, 这样浏览器就能了解这次请求的结果了, 这样就可以调整响应的行为, 例如更新缓存或者是使用本地缓存.
另外, 此时的请求响应头部还是均使用的ASCII编码. 并且此时仍然是每次请求都需求一个新TCP连接, 这是十分浪费性能的. (参考三次握手以及TCP的慢开始)
注意, HTTP/1.0这是一个实验性质的草案版本, 没有作为官方标准来使用过, 因为当时还是有多种实现方案的.
标准建立 - HTTP/1.1
从1997年开始, 为了解决1.0实现混乱, HTTP1.1标准发布, 消除了早先版本很多歧义内容, 并且引入了很多性能优化的特性, 例如长连接, 支持请求基于byte的范围资源, 更好的cache机制, 以及流水线(pipeline).
那么现在一个完整的请求返回大家就很熟悉了:
1 | $> telnet website.org 80 |
由于Host的引入, 我们现在可以把不同域名配置到同一个IP地址的服务器上了. 并且我们可以从头部信息中得到大量的信息, 例如:
- 响应是分块的
- 缓存机制有额外控制
- 内容可以协商, 包括语言, 编码, 内容类型
- 在一次连接中我们同时请求了HTML页面和一个图标文件
- 在第二次连接中我们标明了
Connection: close也就是说我们显式声明了结束连接
事实上, 我们的HTTP/1.1默认情况下就是长连接, 也就是说, 除非你带上了Connection: Close, 否则连接始终都是保持住的, 即时客户端没有带上Connection: Keep-Alive的头部. 但尽管如此, 众多浏览器还是会提供这个头部.
扩展, 进化 - HTTP/1.1+ 与 HTTP/2.0
这个1.1+是我说的, 并不是官方说法. 我们刚刚在上面说过, HTTP头部信息的引入, 为HTTP带来了巨大的可扩展性, 因此从1997年开始, HTTP就一直在扩展.
2000年, 状态层转换出现, 这也就是我们现在常说的REST, 我们通过基本的HTTP/1.1方法里访问特定的URI. 起初, 最早的HTTP1.1有这些动词:
- GET
- POST
- PUT
- DELETE
- TRACE
- OPTIONS
- CONNECT
接着从2010开始, 我们新增了PATCH来部分更新某些资源.
并且从2005年开始, 针对于Web的API大大增加, 由此也引入了很多的新HTTP头部, 例如:
- CORS支持
- DNT隐私控制
- WebSocket以及
Upgrade头部来进行协议升级
经过了15年的发展, 现在到了2020年, 已然是HTTP/2.0的时代了.
为了应对当前越来越复杂的Web页面和Web应用, 数据量也越来越大, 为了能够更快速的传输数据, 早先谷歌使用了一种叫做SPDY的协议, 这可以被视为是HTTP/2.0的雏形.
相较于HTTP/1.1, HTTP/2最大的不同就是成为了二进制协议. 也就是说不能直接可读和手动创建, 除此之外, HTTP/2是一个多路复用的协议, 我们将传输的信息分割成了更小的消息和帧, 然后对他们采用二进制格式的编码.
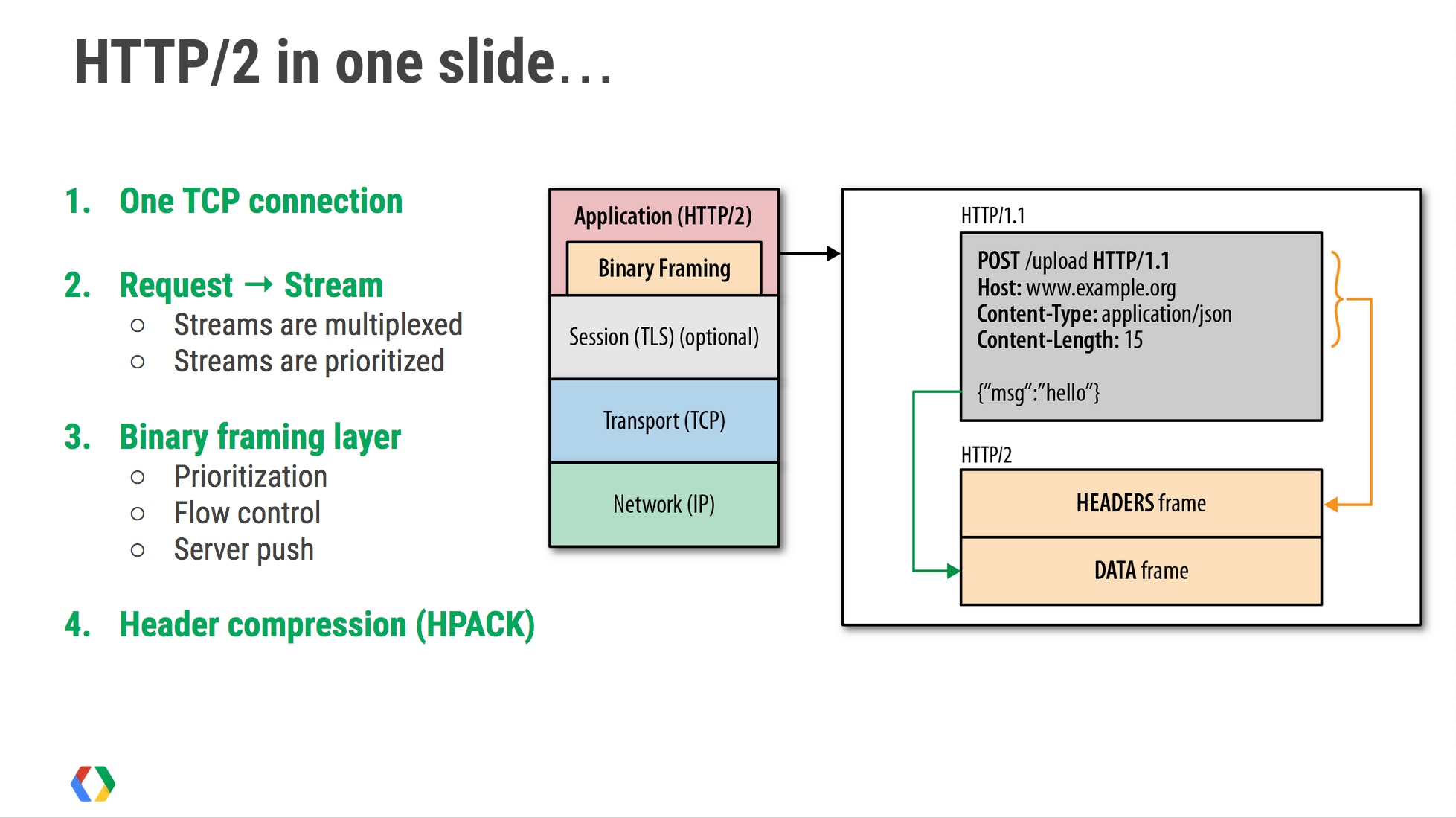
HTTP/2开始强调流的概念了.
流(Stream) – 双向的字节流可以在一次建立的连接中传递多个信息(Message).
信息(Message)在HTTP/2中就是一个完整的帧(Frame)序列, 用来映射逻辑上的请求和响应消息
帧(Frame)就是HTTP/2中最小的单元了 , 每一个帧都包含着一个帧头部, 用来标明这个帧属于哪一个流.
并且从图中我们也能看到, 流是多路复用的, 并且是有优先级的. 而这个二进制帧层也支持流之间的优先级别和依赖关系, 由此更有效率的请求和响应数据. 另外, HTTP/2还可以支持流控和服务端的推流, 以及头部压缩.
然后? – HTTP over QUIC (HTTP/3)?
QUIC的全称是Quick UDP Internet Connections, 也就是使用UDP的快速网络连接. 是由Google在2012年提出的, 相当于重新划分了一次网络分层, 请看:
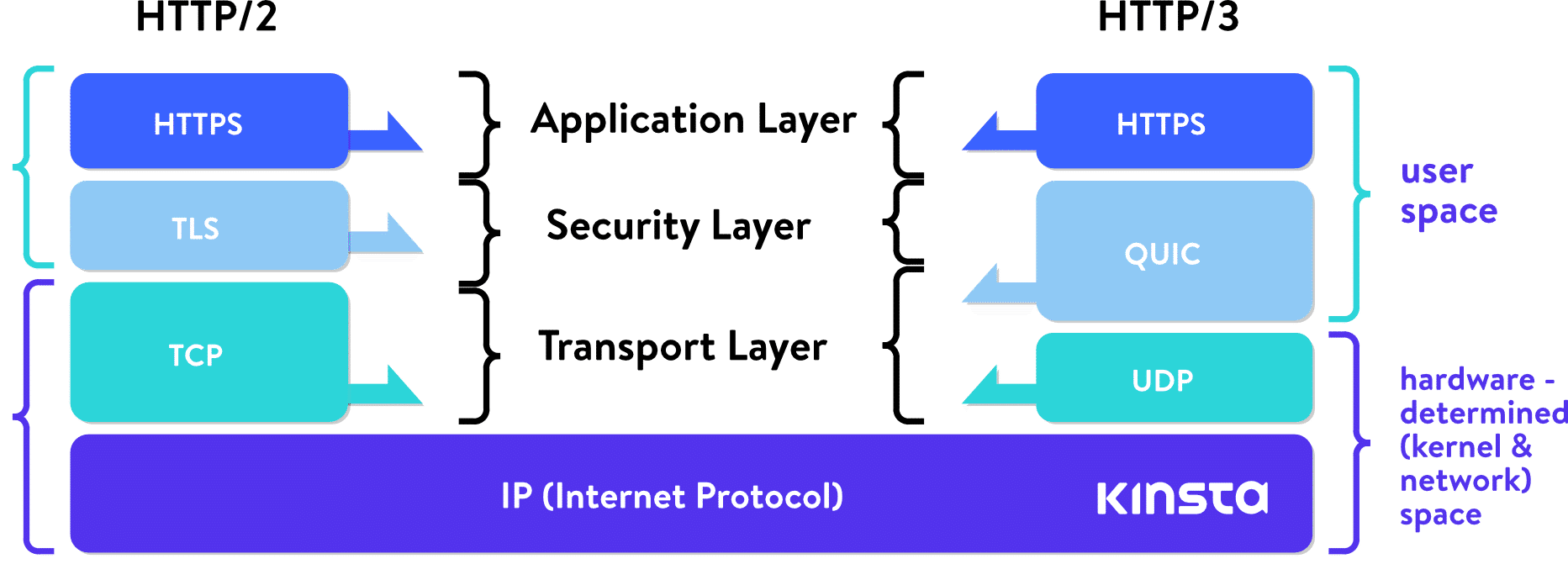
我们刚刚说过, HTTP/2提供了多路复用, 但是这实际上是被TCP限制了. 我们使用一个单一的TCP连接来进行多个流的同时传输, 如果这个时候哪怕只有一个流出现了报文丢失, 整个连接(当然包括该连接下所有的流)都会被劫持, 直到TCP重传. 这个时候, 哪怕是已经传输到目标节点的buffer中了, 也需要一同被阻塞, 直到丢失的报文被重传过来.
而使用了QUIC的话, 就不存在这种问题了. 那么你可能会问, 我如何确保可靠性呢? QUIC同样是个可靠的协议, 不同于TCP的Seq Number, QUIC使用Packet Number来代替, 而每一个Package Number都是严格递增的, 由此避免了原先Seq的歧义性, 另外, QUIC使用Stream Offset来保证数据传输顺序.
QUIC简单总结的话, 相当于是一个4+5+7层协议了.