SchoolOfSRE是 Linkedin 的一个 SRE 基础教程, 里面有一些零碎知识点在这里记录下.
网络部分
这个部分涉及到了 DNS, UDP, HTTP, TCP, IP 路由相关
DNS
看的过程提到了 FQDN, 一时间忘记了是啥. 再来复习一遍:
FQDN: 叫做完全合格域名, fully qualified domain name. 例如, 我们的www.google.com就是 FQDN, 而www, com 这些就不是.
之后教程向我们展示了关于 dig 和 tcpdump 的使用, 简单展示了一个 DNS 查询和响应报文的样子, 然后就是 dig 的一些使用. 不得不说我对于这两个程序的使用还不到家, 只会最简单的使用. 记得复习. ( 而且我发现我没写过关于 tcpdump 的博客呢, 以后或许可以补一下 )
另外忘记了 SOA 是什么, 在这就再把 DNS 的各个记录名字来补充一下:
1 | SOA Start Of Authority, 定义域 |
之后, 教程提到了对于 SRE 来讲 DNS Infrastructure 相关应用, 整理在下:
- DNS 基础设施需要被优化(optimized)或者规划(scaled), 从而让其不要成为系统中的单点故障.
- 系统内部的 DNS 问题会造成微服务 API 调用的问题以及一些连带效应
- DNS 也可以用来做服务发现, 例如: serviceuser.internal.foo.com 能够列出所有在 foo.com 下运行 service user 的实例
- DNS 可以使用 CNAME 可以实现负载均衡, 以 AWS/Azure 的云服务为例, 他们的 CNAME 指向的 A 记录存活时间很短(1 分钟), 因为一种常见的做法是改变 CNAME 指向的 IP 地址来更新负载均衡器的 IP 地址.
- DNS 还可以根据地址位置分布来为用户提供最近的服务的 IP 地址
- DNS Infra 无验证, 因此响应是可以被欺骗的, 我们可以用其他协议例如 HTTPS 来施加保护, 也可使用 DNSSEC 来防止伪造的 DNS 响应.
- 不新鲜的 DNS Cache 可能会造成某些应用请求过期的 API 地址, 从而调用出错.
- DNS 的负载均衡和服务发现还需要关注 TTL, 只有等到 TTL 之后对 DNS 记录进行修改之后, 才能将服务器从池子中移除. 否则一部分流量会因为服务器提前移除而访问失败.
UDP
书接上文, 这里 UDP 的例子就是通过描述 DNS 查询过程来讲解的. 主要是涉及到了两个系统调用, 分别是sendto和recvfrom. 客户内核随机选择一个非特权端口(>1024)作为来源端口, 然后设置目标端口 53, 接着将报文发送到下层.
期间还涉及到了关于多路复用和解复用. 摘录一下:
整体来看, 我们内核的这一过程被称为多路复用(将多个应用的数据包合并到同一个下层)和解复用(将数据包从单个下层隔离到多个应用)
接着简单对比了 TCP 和 UDP, UDP 相较 TCP 更加轻量和用更小的开销来处理通信.
那么对于 SRE 来讲, 和 UDP 相关的有哪些应用呢?
如果我们的下层网络很慢而 UDP 层没法将数据包交付到网络层, sendto系统调用就会被挂起直到内核 buffer 清空. 这样就会影响到整体系统的吞吐能力. 此时可以考虑增加写 buffer 的容量, 涉及到的两个参数:
- net.core.wmem_max
- net.core.wmem_default
同理, 如果上层进程读 buffer 的速度很慢, 内核就需要 drop 掉那些不能进 buffer 队列的数据包(因为此时的 buffer 满了) 而 UDP 不保证数据可靠交付因此就有可能造成数据丢失(除非应用层实现了相关功能), 这个时候我就要增大这两个值来为慢速应用增加缓冲:
- net.core.rmem_default
- net.core.rmem_max
HTTP
之前我有写过关于 HTTP 的历史发展, 其中涉及到了一些 HTTP 的特性. 所以这一部分印象还是蛮深刻的, 教程涉及到的知识点也都理解. 而这部分着重笔墨在了 HTTPS 和 Cookie 上. 因此就跳过了.
TCP
这里 TCP 首先通过tcpdump抓包展示了 TCP 三次握手的过程, 具体解释了其中序列号演变和其中滑动窗口进行流量控制的例子. 另外, 一笔带过了 TCP 的拥堵控制. 最后描述了一遍 TCP 连接断开的过程, 这里关于断开连接一方TIME_WAIT的时间, 解释如下:
一旦服务器端的应用请求调用 close, 服务器端向客户端发送一个 FIN 的报文, 然后客户端进入
TIME_WAIT的状态, 时长是 2*MSS (120s), 这样该时间段内的套接字就不能再被重用, 从而防止因为一些网络中杂散的陈旧数据包到达导致 TCP 状态冲突.
结合 HTTP 和 TCP, 我们在 SRE 中的应用有这些:
- 通过 LB 来增加 HTTP 的性能. 我们有多种不同的 LB, 例如, L4, L7 的负载均衡, DSR(Direct Server Return)
这里穿插一下, 我第一次听说 DSR, 因此去简单了解了一下. 结果看下来, 这不就是 LVS 的 DR 嘛哈哈哈, 被新名词搞傻了. 其实简单说就是为了防止 LB 作为系统性能瓶颈(因为在 C2S, S2C 路径上, 请求响应流量很多)
- 微调
rmem和wmem能够增加发送方和接收方的吞吐量 net.ipv4.tcp_max_syn_backlog和net.core.somax.conn决定在上层应用调用accept之前, 内核能完成多少数量的连接握手. 这对于一些单线程应用来说很有用, 一旦积压满了, 新的连接就会保持在SYN_RCVD的状态, 直到应用调用ACCEPT.- 当短连接很多的时候, 应用有可能会跑完所有的文件描述符, 这个时候我们需要来考察
net.ipv4.tcp_tw_recycle和net.ipv4.tcp_tw_reuse从而减少呆在 timewait 状态的时间(当然这样像上文说的是有风险的), 让应用重用连接池而不是创建临时连接也有帮助. - 通过考察性能指标, 来分清楚是 App 的问题还是网络侧的问题能够帮助我们理解性能瓶颈所在. 例如当很多套接字在
close_wait状态, 是应用上的问题. 而重传可能更多是网络和操作系统网络栈的问题, 而不是应用本身的问题. 通过理解基本原理能够让我们缩小范围来找到真正的系统瓶颈.
Routing
上面已经介绍过了应用层的 HTTP, 传输层的 UDP 和 TCP, 那么接下来就是网络层的路由部分了.
这里首先是展示了内核 IP 路由表, 接着告诉我们匹配规则是做AND操作, 通过将目标 IP 和掩码做位与操作, 然后根据结果选择适当的路由决策. 如果所有的条目都不匹配, 就会和0.0.0.0做位与操作, 也就是我们所说的默认路由
接着来说些应用:
- 一般来说路由表是由 DHCP 生成的, 因此手动调整不是个好的实践.
- 理解错误信息能够帮我们很快的定位问题
- 在一些少见的场合, 通过检查 ARP 表能够帮助我们了解到是否有 IP 冲突
Python 和 Web 部分
在这个部分, 涉及到了关于 Python 的一些基本概念, Web 应用(以 Flask 框架为例), 以及一个URL Shortening的案例设计的例子.
编译 VS 解释
首先是关于 Python 和 C/C++以及 Java 的对比. 从某种角度来说 Python 也算是编译语言, 他有自己的内置编译器. 类比 Java, Java 会生成一个.class的类文件, 也就是我们所熟悉的bytecode. 而 Python 也类似这样, 而区别在于 Python 不需要单独的编译命令来运行一个 Python 程序. 除此以外, Java 是静态强类型语言, 因此编译器是在编译阶段可以知道类型相关的错误的, 而 Python 是动态语言, 直到程序运行, 我们都不会知道类型的. 因此, Python 的编译器更加dumb一点, 或者说没有 Java 的严格.
但不管怎么说, 当涉及到 Python 程序运行的时候, 一定会有编译的步骤. 这个我们在之前说 Python 的对象机制的时候就知道, 我们通过使用dis模块来查看了 Python 运行的bytecode. 这一点就和 C/C++又不一样了, C/C++会生成机器码而不是字节码.
对于机器码, 可以直接交给我们的 OS 来执行, 而字节码就不是这样了. 对于字节码, 我们需要对应的虚拟机, 例如 JVM, CPython, Jython 等等. 虚拟机也就是读取字节码并且在给定的操作系统上运行的程序.
一些 Python 的概念
万物皆对象, 这个在我们之前的 Python 源码阅读中也有所了解. 像我们的函数, 列表等数据结构, 类, 模块, 运行的函数, 都是对象.
接着是关于 Python 执行上下文, 或者说命名空间, 我们可以通过locals()来查看 当前上下文中定义的对象. 接着教程像我们展示了函数作为对象的特性. 我们可以通过dir()来查看一个对象包含的对象.
另外, 还有__globals__可以让我们访问到当前的全局变量.
接着介绍了一个有趣的对象__code__, 因为万物皆对象, 包括我们的字节码也是对象, 因此我们可以通过访问__code__来做一些很有趣的事情, 例如获取文件名, 参数, 变量列表, 甚至字节码本身.
装饰器. Python 可以使用装饰器来对函数附加一些额外功能. 顺带一提, 之前有在一些面试资料里面了解到, 装饰器的设计模式叫做**AOP (Aspect-oriented Programming)**, 即面向切面编程. 我们在运行时, 动态将代码加入到类的指定位置, 指定方法上.
接着说一些小 tip 类东西:
- Python 构建原型非常迅速, 因为有大量的库可以使用, 这个时候我们的代码库往往会十分复杂, 类型错误就会更加普遍, 而由于 Python 的弱类型特性, 应付起来会更加困难.
- 因为 Python 是动态类型语言, 也就意味着我们的类型是在运行时决定的, 相较其他静态类型语言, Python 运行的十分缓慢.
- Python 拥有
GIL, 即全局解释器锁, 会成为在多核并行计算的限制因素 - 一些鲜为人知的 Python 特性: https://github.com/satwikkansal/wtfpython
Python, Web 和 Flask
这一部分简单介绍了 Python 的 Socket 变成和 Flask 框架的简述, 没啥意思, 跳过啦
URL Shortening App 的设计
这里构建了一个十分简单的短 URL 应用, 仅仅实现了一个 API. 我们来看看在实际编程之前做了什么事情吧.
- 上层操作和 API 端点
因为是一个短链接生成应用, 我们会需要一个 API 来生成, 以及一个 API 或者访问端点来接受短链接并且重定向到原始 URL 上去. 这两个 API 应该就能够让 App 的功能正常运行并且可以被任何人调用
- 如何缩短 URL?
给定一个 URL, 我们需要生成一个缩短版的. 一种方法就是使用随机字符. 另外一种方案是使用某种哈希算法. 好处就是我们可以对相同的 URL 重用同样的短链接. 那么关于哈希碰撞呢? 即时在随机字符的方案中, 哈希碰撞也是有可能发生的. 在这种场合下, 我们也许可以通过结果前后增加随机值来避免冲突.
另外, 不同哈希算法的选择也至关重要. 我们将会需要分析不同的算法. CPU 需求和他们的性质.
- URl 合法吗?
如何验证一个 URL 是合法的? 我们是需要验证还是要鉴定真实性? 常规检查可以通过正则匹配来完成. 或者我们会尝试去访问该 URL. 有这些陷阱我们需要留意:
- 我们需要定义那些情况是成功(建立基准线): HTTP 200?
- 如果 URL 是在私有网络中呢?
- 如果该 URL 暂时停止服务了呢?
- 存储
我们如何让持久化数据呢? 有不同的数据库选择, 关系型数据库 MySQL 还是 NoSQL 数据库呢? 关于这点会在下面的数据章节详述.
小节
在这里我们将从应用规模化, 监控策略, SRE 应用三个方面来做小节
规模化应用
书接上文, 我们设计和开发了应用, 那么接下来我们就要简历持续集成和持续交付的流水线(pipeline). 最后我们还需要把这个应用部署到什么地方.
最初我们可能就只是把应用部署到单一虚拟机或者任意云服务提供商. 但是这是一个单点(Single point of failure), 这对于 SRE(或者哪怕说对于一个工程师)来说都是不允许的. 因此这里我们考虑的一个提升就是在负载均衡之后部署复数个应用实例.
尽管可以增加更多的实例, 但在增加到某一个节点的时候系统的其他瓶颈会显露出来, 例如: DB 或者是负载均衡本身. 那么我们怎样才能知道瓶颈在哪里呢? 我们需要能够对应用架构中的各个部分进行观察. 也就是这样, 我们才能知道指标, 从而知道哪里出了问题. What gets measured, gets fixed!
更多我们后面的scalability module的章节涉及到.
监控策略
一旦我们的应用部署好了, 他就可以正常运行了. 但是不可能永远都能正常提供服务. 既然可靠性都写在 SRE 的 title 里面了, 因此我们需要通过设计让系统运行可靠运行. 但是往往事与愿违, 机器会出问题, 磁盘可能也会有问题, 有问题的代码也有可能会被推送到生产环境上去. 而这些可能的场景都会让我们的系统更加的不可靠. 那么这个时候咋办呢? 当然就是监控了.
如果系统出现问题, 或者说出现了我们没有预料到的情况, 我们希望能够收到警告. 那么以上面的例子(URL Shortening App)来说, 我们可以怎么监控呢?
- 因为这是个 WebApp, 接受 HTTP 请求, 因此我们可以关注 HTTP 状态码和延迟.
- 请求容量也是我们需要关注的一个指标, 例如当 app 收到不寻常的请求流量, 应该有什么地方出问题了.
- 我们也想关注一下数据库. 当然这取决于我们要选择什么样的数据库解决方案. 一般有查询时间, 容量, 磁盘使用率等等.
- 最后, 我们还需要跑一些外部的监控, 用来模拟在用户的角度, 系统工作是否正常
数据
在这个部分, 我们会涉及到关系型数据库和 NoSQL 数据库以及部分大数据的内容.
关系型数据库
首先是对于数据库相关基本概念的介绍, 包括关系型数据库本身, 事务, ACID, CRUD 操作, 约束, 索引, 连接, ACL. 接着是说了一些流行的数据库产品, 例如商业闭源的 - Oracle, MicroSoft SQL Server, IBM DB2. 开源的 - MySQL, MariaDB, PostgreSQL.
以 MySQL 为例, 附一张 MySQL 的架构图:
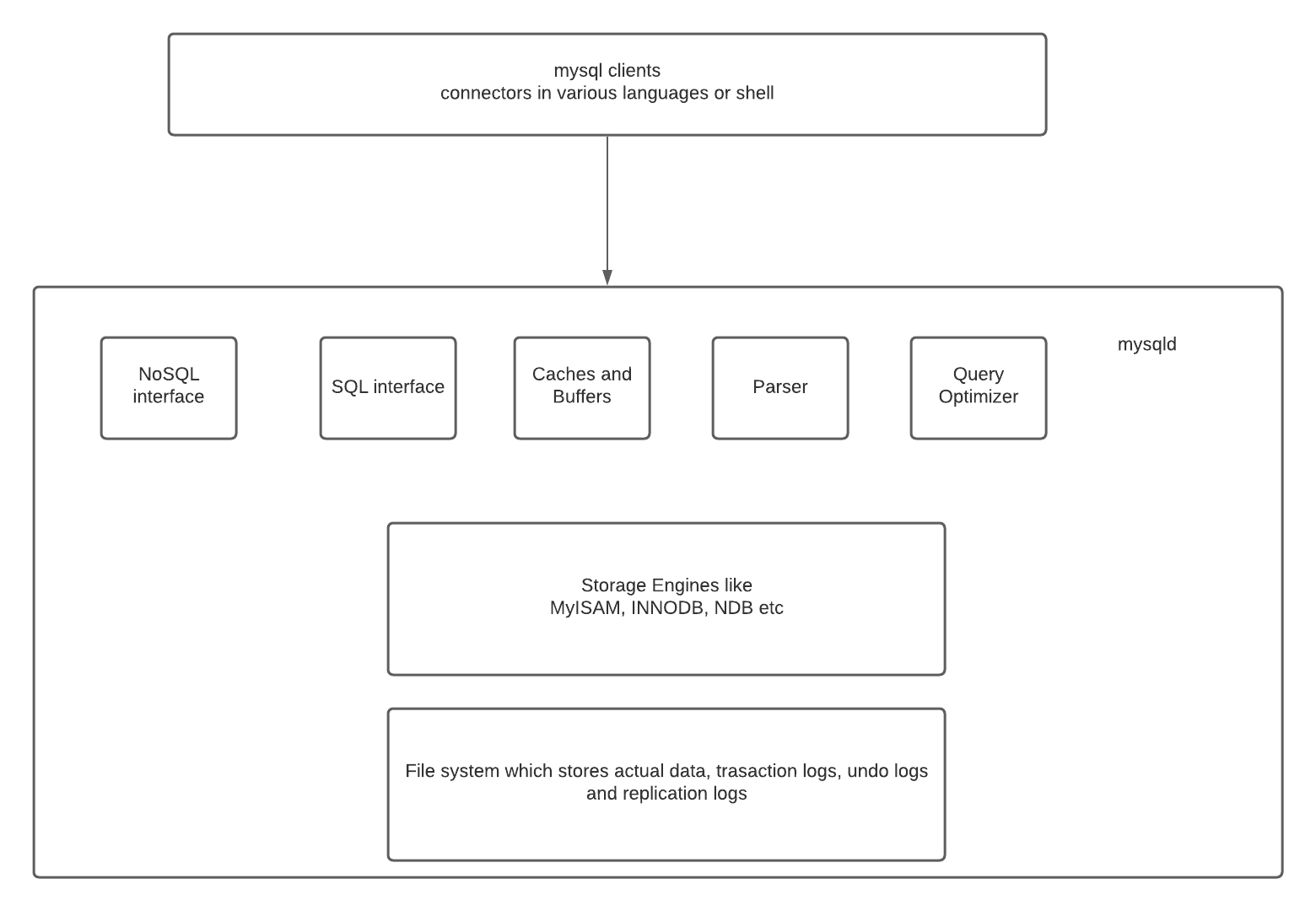
接着是分开应用层, Server 层来分别介绍各个层的组件和负责的功能.
应用层: 连接处理, 身份验证, 安全. 服务器层: 服务和 utils - 备份/恢复, 复制, 集群功能等等, SQL 接口, SQL 分析器, 查询优化器, Cache 和 Buffer.
另外, 我们还有这些常见存储引擎: InnoDB, MyISAM, Archive, Memory, CSV, …等等.
关于 MySQL 的部分, 之前的文章有更详细的描述, 但是现在一看自己确实忘得也差不多了, 还是要多复习呀!
以, InnoDB 为例, 我们来看下架构图:
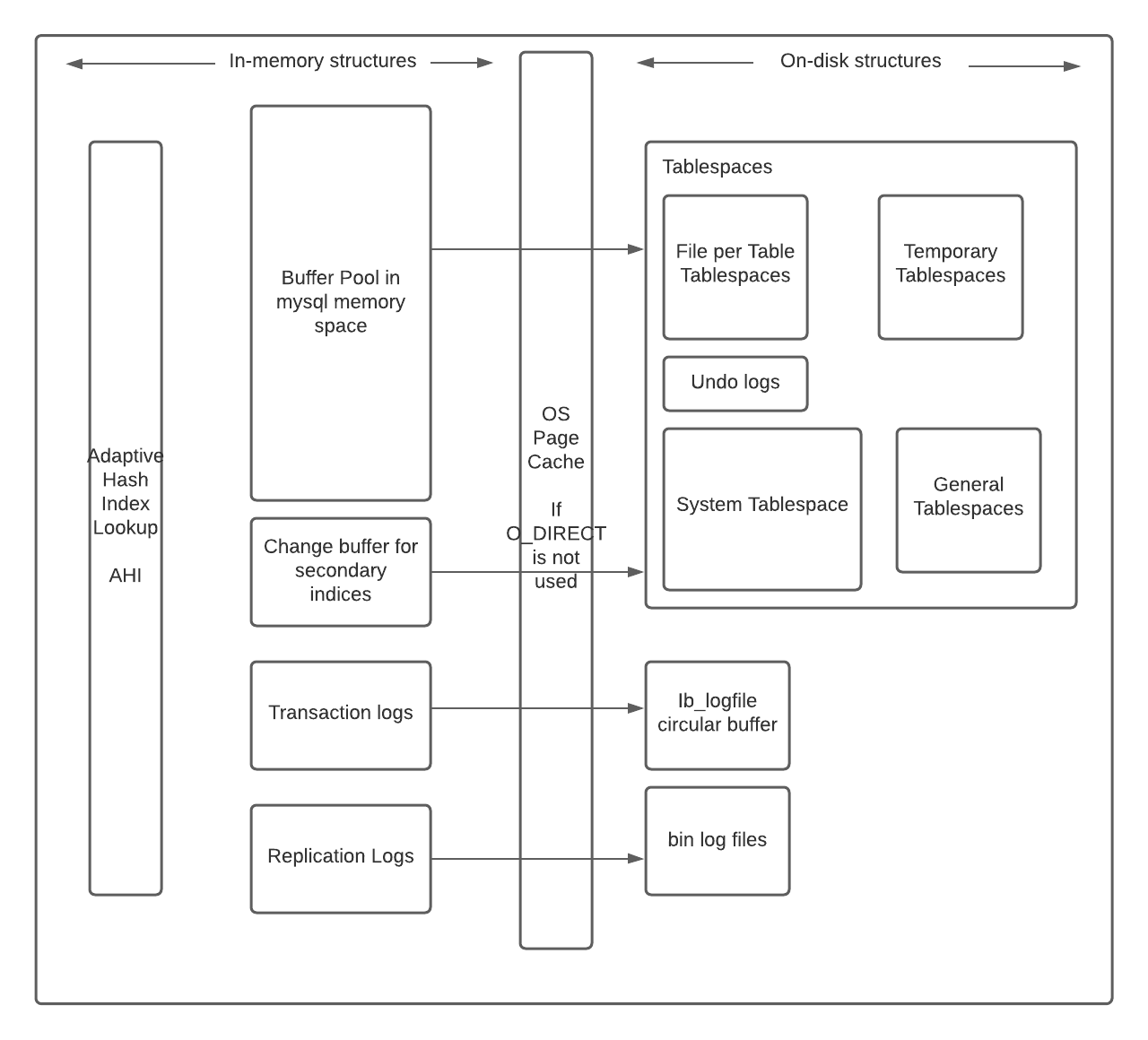
InnoDB 是通用性最好的存储引擎了, 提供行级别的锁, ACID 支持, 事务支持, 崩溃回复和多版本并发控制等特性.
从架构图我们能很明显看到, InnoDB 分成两个部分, 在磁盘的部分和内存中部分.
在内存中, InnoDB 有这些关键组件:
- 缓冲池: 常用数据(表和索引)的 LRU 缓存
- 变化缓冲:
- 适应哈希索引: 通过快速哈希查找表补充 InnoDB 的 B 树索引. 未命中会有性能损失.
- 日志缓冲: 见名知意, 存储那些没来得及刷新到磁盘的日志数据
这些组件的内存都是可配置的, 这些配置项都会影响到 InnoDB 的性能. 调整这些需要对工作负载仔细的分析, 资源压测以及校准.
而在磁盘上, 我们有这些:
- 表文件
- 索引文件
- 重做日志
- 撤销日志
NoSQL
一个常见的误解就是 NoSQL 数据库或者非关系型数据库不能很好的存储关系型数据. 事实上, 他们只不过是用的另外一种方式来存储数据而已, 并且, 很多 NoSQL 数据库在建模关系型数据上, 较之关系型数据库要更加容易, 因为关联的数据没有被分成表.
我们可以把 NoSQL 数据库分成这四类:
- 文档数据库: 文档类似 JSON, 每一个文档都包含域和对应的值. 数据模型直观, 结构灵活. e.g: MongoDB, Couchbase
- 键值对数据库: 适合存储大量数据但不需要复杂的查询. e.g: Redis
- 宽列数据库: 数据可以存储到表, 行, 动态的列中. 灵活, 因为每一行不要求有同样的列. 常见存储 IoT 和用户档案数据. e.g: Cassandra, HBase
- 图数据库: 数据被存储在节点和边中. 节点一般是信息而边一般都是存储这些节点之间的关系. e.g: Neo4j
NoSQL 简单总结下来, 有更灵活的数据模型. 并且更容易进行水平扩展, 通常能够执行比传统 SQL 系统更快的查询(非范式设计, 水平扩展). 另外, NoSQL 通常可以直接将数据映射到对应的编程语言数据结构上(相对 SQL DB 而言, 不太需要 ORM)
关键概念
这里我们来看下对于 NoSQL 或者分布式系统来说的一些关键概念.
CAP 理论
所谓 CAP 理论是 2000 年由 Eric Brewer 在 ACM’s PODC 讨论会的一个”Towards Robust Distributed Systems”提出的. 而 CAP 也就是一致性, 可用性, 分区容错的首字母缩略. 针对每一个特性, 来展开说.
- Consistency - 一致性
简单的说, 这就是指系统在一次执行之后能有多一致. 所以一致就是指在一个分布式系统中, 一个源所作的写操作对该资源的所有读者可用. 不同的 NoSQL 系统支持不同等级的一致性.
- Availablity - 可用性
可用性就是指系统如何应对不同系统当硬件或软件故障的时候导致失去部分功能. 而高可用就是指即使当系统中某些部分下线(故障或更新)的时候系统依然可用, 能够对读写操作进行处理.
- Partition Tolerance - 分区容错
指系统在网络分区的情况下继续运行的能力. 所谓网络分区就是节点之间的网络出故障而节点之间无法通信. (形成了多个”岛”, 系统之间无法在岛之间通信)
通常来说, P 我们必须满足, 那么接下来 C 和 A 就要选其一了. 而一般来说, A 要比 C 更有价值一些. 但我们肯定也不是放着 C 就不管了. 通常我们会追求最终一致性.
所谓最终一致性就是指随着时间推移, 所有的读者都会看到写入的内容: “在稳定状态下, 系统最后都会返回最后的写入值”. 因此在更新过程中, 客户端会面临一个数据的非一致状态.
NoSQL 系统支持不同等级的最终一致性模型, 例如:
- 读自己写一致性
客户端在写操作之后能立即看到其更新. 但是读取的内容有可能会命中写入节点意外的节点, 这个时候就不会立即看到其他客户的更新.
- 会话一致性
客户端能够在会话空间内看到对他们数据的更新. 这个时候通常读操作和写操作发生在同一个服务器上. 其他使用同一个节点的客户端会收到同样的更新.
- 因果一致性
下列情况, 系统将会提供因果一致性: 由潜在因果关系相关的写操作会被系统的每个进程顺序看到. 不同进程会以不同的顺序观察到并发的写入操作.
如果不太可能进行同分区数据的并发更新, 或者客户端不会立即依赖读到自己或者其他客户端发布的更新, 那么这个时候就可以考虑最终一致性了.
接着来看看在分布式系统中, 数据的版本管理相关.
数据多版本
我们的数据有可能在不同的节点中同时间被修改(假设现在是严格的一致性). 这样并发的更新修改就会出现冲突, 此时我们就需要一些冲突的解决方法, 常见的有这些:
- 时间戳
这就很简洁明了了, 我们记录修改时间然后选择最新的, 但是提到时间, 这就依赖我们 infra 中不同组件之间的时间同步了. 如果是异地会变得更麻烦点.
- 乐观锁
所谓乐观锁其实就是我们在每一次数据更新都会关联一个特殊的值, 类似版本号或者是时钟. 当客户端更新数据的时候, 需要指明是哪个版本的数据. 但这样的话, 我们就需要持续记录每一个数据版本
- 向量时钟
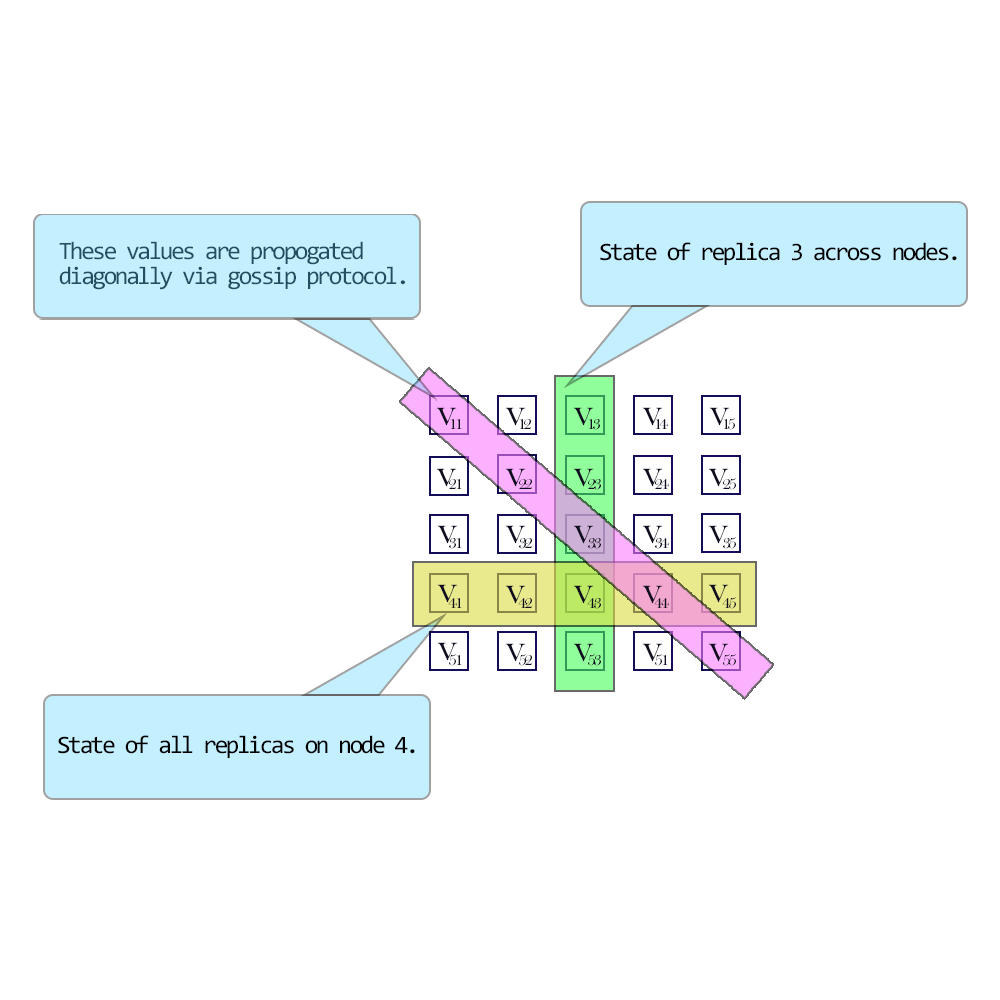
一个向量时钟是一个保存了各个节点时钟数值的元组. 在我们的分布式环境中, 每一个节点都维护这个一个代表节点自己和该节点的副本状态的时钟值的元组. 这里的时钟数值可以是从本地时钟或者版本号中获取的实时时间戳.
向量时钟有这样的优点:
- 对同步时钟没有依赖
- 不需要对版本号做总排序
- 不需要在不同的节点上存储和维护多版本的数据
分区
当数据有了一定的量之后, 我们就需要考虑进行数据分区, 创建副本来进行负载均衡和灾难恢复了. 常见的方法思路如下:
- 内存缓存 (常见的例如: memcache / redis)
- 集群
- 读写分离
- 数据分片
哈希
哈希的本质其实就是将数据映射到另一种数据, 通常来说对象数据类型都是整数, 也就是我们常说的hash code. 举一个最简单的例子, 在我们的一个数据集群中, 我们可以这样简单的取模来获取数据分片存放的位置
1 | p = k mod n |
这里
1 | p -> 集群分区 |
但显而易见的问题是, 当我们的集群拓扑结构改变的时候, 数据分布自然也会发生改变. 例如当我们有节点离开或者有新节点加入到我们的集群中的时候. 这个时候我们就考虑:
一致性哈希
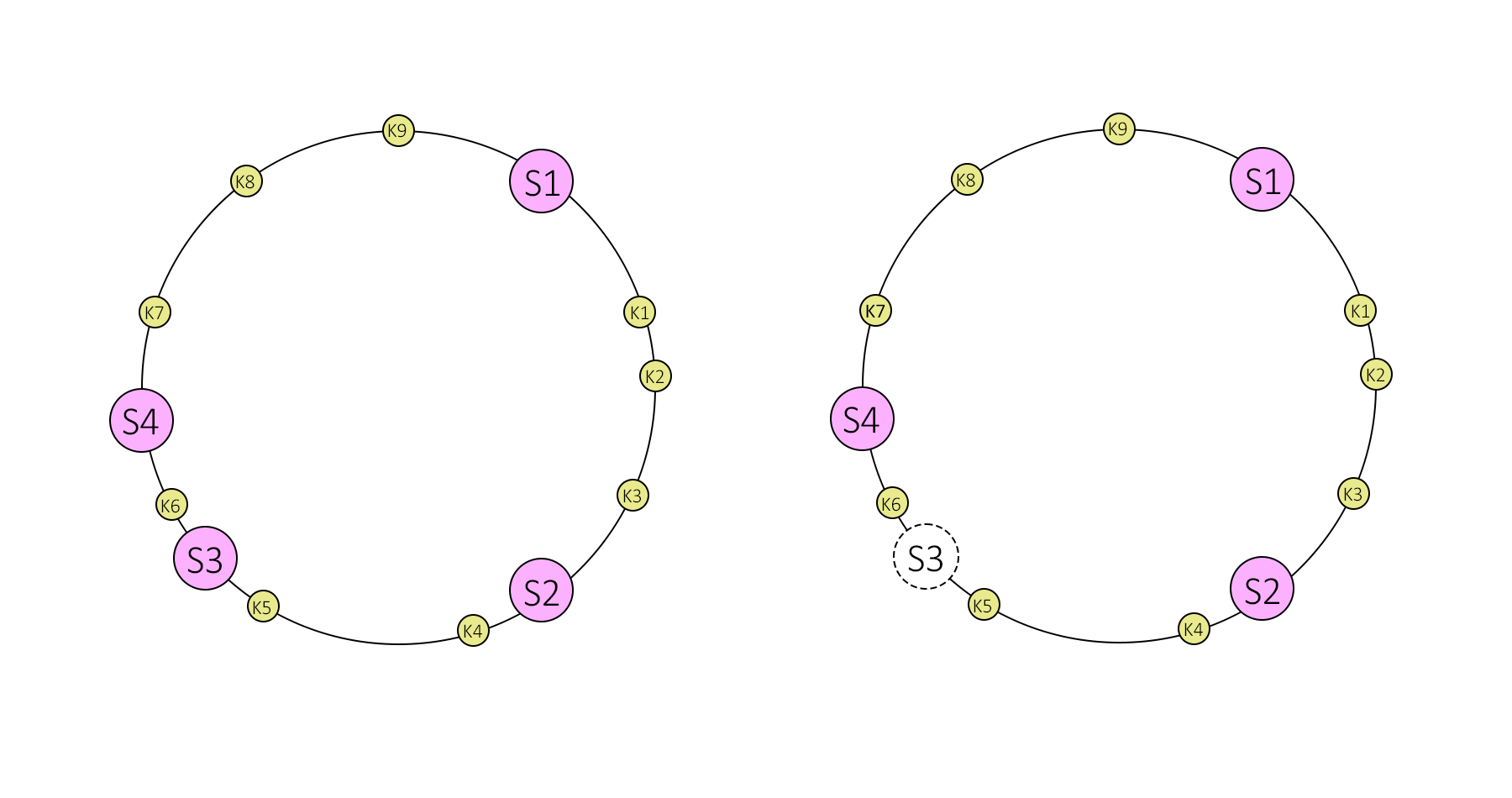
一致性哈希最经典的解释就是哈希环, 如上图所示.
简单的说, 假设我们的哈希函数h()能够生成一个 64 位的整数, 然后这些个数就会在这个环上均匀分配, 之后相当于根据机器的权重我们把节点丢到环上, 每一个节点的自己的 hash h(s) 都会是一个大于我们要寻找的数据哈希h(k)的最小值. 之后当我们需要寻找h(k)的时候, 我们只需要顺着这个环从h(k)找下去就可以找对存储这个数据副本对应的节点了.
在这个模型下,如果有节点离开集群, 我们就可以将对应的副本复制到下一个节点中, 算是解决了上述的问题. 但显然的, 这样会增大承接这些数据副本的节点的负载, 从而导致节点之间的负载不平衡. 对此, 为了能够均匀分配这些数据, 我们可以对每一个节点都创建一批固定数量的虚拟节点, 之后在均匀的丢到环上, 例如节点 S1, 我们可以分成 S11, S12, S13,…, 节点 S2, 我们有 S21, S22, S23, …, 之后对应到节点 Sij 的数据都会被存储在节点 Si 上.
这样假设当 S3 离开集群的时候, S31, S32, …也会被移除, 此时我们只需要将这些虚拟节点的 key 自动落到他们之后的虚拟节点就好了, 由于这些节点是均匀的落在环上的, 这样承接这些数据的节点就会是: S1?, S2?, S4?, ….
你说如果增加节点会怎样? 类似的, 当我们来了一个新的节点 S5, 我们还是会先创建多个虚拟节点并标记为 S51, S52, …之后均匀的丢到环上, 这样在理想情况下, 就会有 1/4 分别来自 S1, S2, S4 的数据会分给 S5.
注意啊, 这小节里面提到的均匀并不是绝对的, 当我们的机器节点性能不同的时候, 或者是我们有其他的需要, 分布都可能不是均匀的.
Quorum
仲裁只有可能在我们的集群节点数量满足最小要求的时候才会发生. majority通常是(n/2 + 1), n 就是集群节点数量.
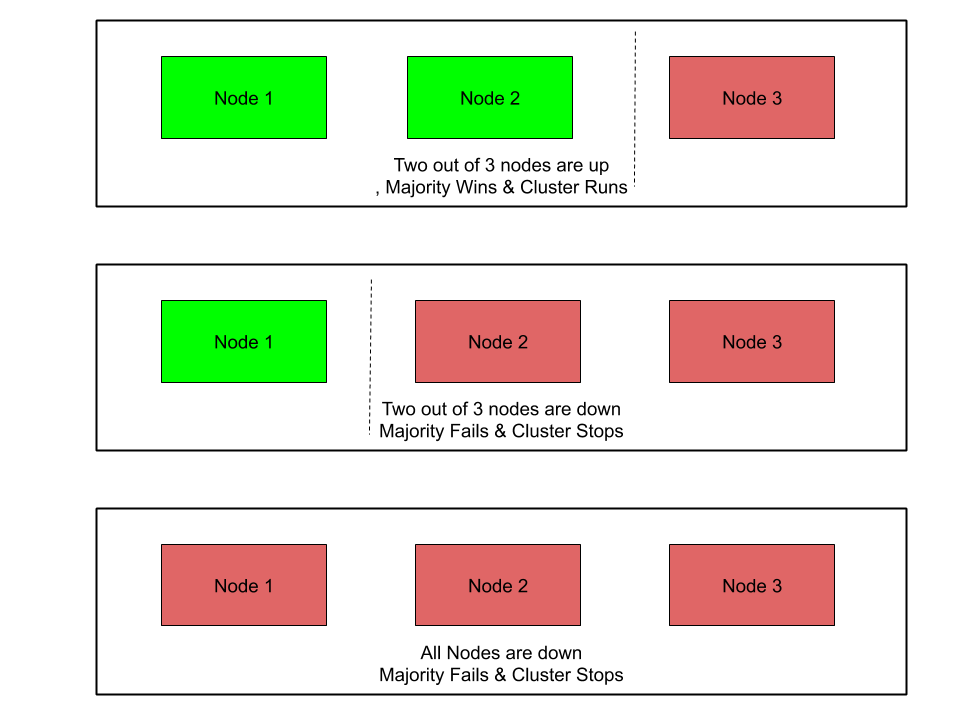
在我们之前提到的网络分区中, 当出现网络问题导致分区中的一部分节点不能和另外一部分通信时, 我们就会需要quorum来决定是不是要继续运行集群, 如果满足majority, 则这些节点留下, 集群继续运行. 其余的节点会被踢出集群. 另外, 当我们的这里的majority选取不当的时候, 例如 6 节点集群中我们选了 3, 则有可能会发生脑裂, 需要注意.
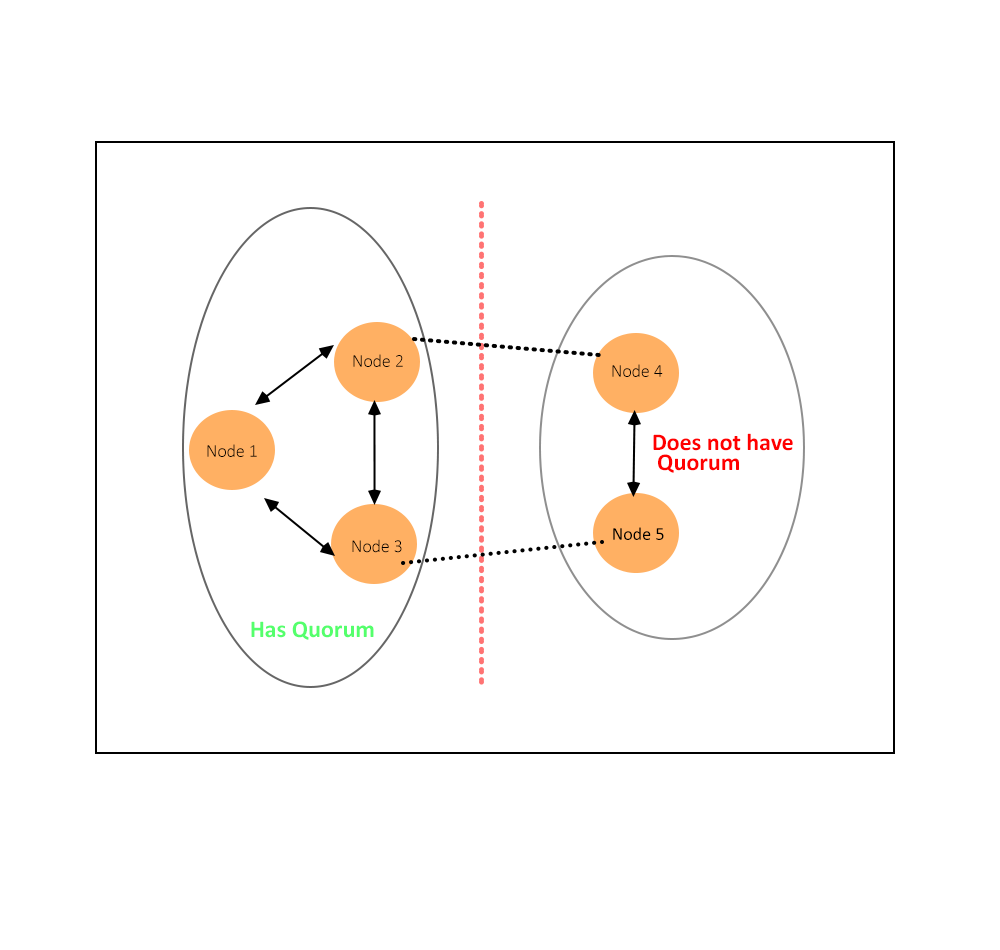
当然啦, 只要还能正常运作的节点都会持续通信, 这样当网络恢复的时候, 集群就可以重建.